Функции модуля threading
В модуле threading, который здесь используется, есть функции, позволяющие получить информацию о потоках:
activeCount() Возвращает количество активных в настоящий момент экземпляров класса Thread. Фактически, это len(threading.enumerate()).currentThread() Возвращает текущий объект-поток, то есть соответствующий потоку управления, который вызвал эту функцию. Если поток не был создан через модуль threading, будет возвращен объект-поток с сокращенной функциональностью (dummy thread object).enumerate() Возвращает список активных потоков. Завершившиеся и еще не начатые потоки не входят в список.
Класс Thread
Экземпляры класса threading.Thread представляют потоки Python-программы. Задать действия, которые будут выполняться в потоке, можно двумя способами: передать конструктору класса исполняемый объект и аргументы к нему или путем наследования получить новый класс с переопределенным методом run(). Первый способ был рассмотрен в примере выше. Конструктор класса threading.Thread имеет следующие аргументы:
Thread(group, target, name, args, kwargs)
Здесь group - группа потоков (пока что не используется, должен быть равен None), target - объект, который будет вызван в методе run(), name - имя потока, args и kwargs - последовательность и словарь позиционных и именованных параметров (соответственно) для вызова заданного в параметре target объекта. В примере выше были использованы только позиционные параметры, но то же самое можно было выполнить и с применением именованных параметров:
import threading
def proc(n): print "Процесс", n
p1 = threading.Thread(target=proc, name="t1", kwargs={"n": "1"}) p2 = threading.Thread(target=proc, name="t2", kwargs={"n": "2"}) p1.start() p2.start()
То же самое можно проделать через наследование от класса threading.Thread с определением собственного конструктора и метода run():
import threading
class T(threading.Thread): def __init__(self, n): threading.Thread.__init__(self, name="t" + n) self.n = n def run(self): print "Процесс", self.n
p1 = T("1") p2 = T("2") p1.start() p2.start()
Самое первое, что необходимо сделать в конструкторе - вызвать конструктор базового класса. Как и раньше, для запуска потока нужно выполнить метод start() объекта-потока, что приведет к выполнению действий в методе run().
Жизнью потоков можно управлять вызовом методов:
start()Дает потоку жизнь.run()Этот метод представляет действия, которые должны быть выполнены в потоке.join([timeout])Поток, который вызывает этот метод, приостанавливается, ожидая завершения потока, чей метод вызван.
Параметр timeout (число с плавающей точкой) позволяет указать время ожидания (в секундах), по истечении которого приостановленный поток продолжает свою работу независимо от завершения потока, чей метод join был вызван. Вызывать join() некоторого потока можно много раз. Поток не может вызвать метод join() самого себя. Также нельзя ожидать завершения еще не запущенного потока. Слово "join" в переводе с английского означает "присоединить", то есть, метод, вызвавший join(), желает, чтобы поток по завершении присоединился к вызывающему метод потоку.getName()Возвращает имя потока. Для главного потока это "MainThread".setName(name)Присваивает потоку имя name.isAlive()Возвращает истину, если поток работает (метод run() уже вызван, но еще не завершился).isDaemon()Возвращает истину, если поток имеет признак демона. Программа на Python завершается по завершении всех потоков, не являющихся демонами. Главный поток демоном не является.setDaemon(daemonic)Устанавливает признак daemonic того, что поток является демоном. Начальное значение этого признака заимствуется у потока, запустившего данный. Признак можно изменять только для потоков, которые еще не запущены.
В модуле Thread пока что не реализованы возможности, присущие потокам в Java (определение групп потоков, приостановка и прерывание потоков извне, приоритеты и некоторые другие вещи), однако они, скорее всего, будут созданы в недалеком будущем.
Когда нужны замки?
Замки позволяют ограничивать вход в некоторую область программы одним потоком. Замки могут потребоваться для обеспечения целостности структуры данных. Например, если для корректной работы программы требуется добавление определенного элемента сразу в несколько списков или словарей, такие операции в многопоточном приложении следует обставить замками. Вокруг атомарных операций над встроенными типами (операций, которые не вызывают исполнение какого-то другого кода на Python) замки ставить необязательно. Например, метод append() (встроенного) списка является атомарной операцией, а тот же метод, реализованный пользовательским классом, может требовать блокировок. В случае сомнений, конечно, лучше перестраховаться и поставить замки, однако следует минимизировать общее время действия замка, так как замок останавливает другие потоки, пытающиеся попасть в ту же область программы. Отсутствие замка в критической части программы, работающей над общими для двух и более потоков ресурсами, может привести к случайным, трудноуловимым ошибкам.
Модуль thread
По сравнению с модулем threading, модуль thread предоставляет низкоуровневый доступ к потокам. Многие функции модуля threading, который рассматривался до этого, реализованы на базе модуля thread. Здесь стоит сделать некоторые замечания по применению потоков вообще. Документация по Python предупреждает, что использование потоков имеет особенности:
Исключение KeyboardInterrupt (прерывание от клавиатуры) может быть получено любым из потоков, если в поставке Python нет модуля signal (для обработки сигналов).Не все встроенные функции, блокированные ожиданием ввода, позволяют другим потокам работать. Правда, основные функции вроде time.sleep(), select.select(), метод read() файловых объектов не блокируют другие потоки.Невозможно прервать метод acquire(), так как исключение KeyboardInterrupt возбуждается только после возврата из этого метода.Нежелательно, чтобы главный поток завершался раньше других потоков, так как не будут выполнены необходимые деструкторы и даже части finally в операторах try-finally. Это связано с тем, что почти все операционные системы завершают приложение, у которого завершился главный поток.
О потоках управления
В современной операционной системе, даже не выполняющей ничего особенного, могут одновременно работать несколько процессов (processes). Например, при запуске программы запускается новый процесс. Функции для управления процессами можно найти в стандартном модуле os языка Python. Здесь же речь пойдет о потоках.
Потоки управления (threads) образуются и работают в рамках одного процесса. В однопоточном приложении (программе, которая не использует дополнительных потоков) имеется только один поток управления. Говоря упрощенно, при запуске программы этот поток последовательно исполняет встречаемые в программе операторы, направляясь по одной из альтернативных ветвей оператора выбора, проходит через тело цикла нужное число раз, выбирается к месту обработки исключения при возбуждении исключения. В любой момент времени интерпретатор Python знает, какую команду исполнить следующей. После исполнения команды становится известно, какой команде передать управление. Эта ниточка непрерывна в ходе выполнения программы и обрывается только по ее завершении.
Теперь можно представить себе, что в некоторой точке программы ниточка раздваивается, и каждый поток идет своим путем. Каждый из образовавшихся потоков может в дальнейшем еще несколько раз раздваиваться. (При этом один из потоков всегда остается главным, и его завершение означает завершение всей программы.) В каждый момент времени интерпретатор знает, какую команду какой поток должен выполнить, и уделяет кванты времени каждому потоку. Такое, казалось бы, незначительное усложнение механизма выполнения программы на самом деле требует качественных изменений в программе - ведь деятельность потоков должна быть согласована. Нельзя допускать, чтобы потоки одновременно изменяли один и тот же объект, результат такого изменения, скорее всего, нарушит целостность объекта.
Одним из классических средств согласования потоков являются объекты, называемые семафорами. Семафоры не допускают выполнения некоторого участка кода несколькими потоками одновременно.
Самый простой семафор - замок (lock) или mutex (от английского mutually exclusive, взаимоисключающий). Для того чтобы поток мог продолжить выполнение кода, он должен сначала захватить замок. После захвата замка поток выполняет определенный участок кода и потом освобождает замок, чтобы другой поток мог его получить и пройти дальше к выполнению охраняемого замком участку программы. Поток, столкнувшись с занятым другим потоком замком, обычно ждет его освобождения.
Поддержка многопоточности в языке Python доступна через использование ряда модулей. В стандартном модуле threading определены нужные для разработки многопоточной (multithreading) программы классы: несколько видов семафоров (классы замков Lock, RLock и класс Semaphore) и другие механизмы взаимодействия между потоками (классы Event и Condition), класс Timer для запуска функции по прошествии некоторого времени. Модуль Queue реализует очередь, которой могут пользоваться сразу несколько потоков. Для создания и (низкоуровневого) управления потоками в стандартном модуле thread определен класс Thread.
Очередь
Процесс, показанный в предыдущем примере, имеет значение, достойное отдельного модуля. Такой модуль в стандартной библиотеке языка Python есть, и он называется Queue.
Помимо исключений - Queue.Full (очередь переполнена) и Queue.Empty (очередь пуста) - модуль определяет класс Queue, заведующий собственно очередью.
Собственно, здесь можно привести аналог примера выше, но уже с использованием класса Queue.Queue:
import threading, Queue
item = Queue.Queue()
def consume(): """Потребление очередного элемента (с ожиданием его появления)""" return item.get()
def consumer(): while True: print consume()
def produce(i): """Занесение нового элемента в контейнер и оповещение потоков""" item.put(i)
p1 = threading.Thread(target=consumer, name="t1") p1.setDaemon(True) p2 = threading.Thread(target=consumer, name="t2") p2.setDaemon(True) p1.start() p2.start() produce("ITEM1") produce("ITEM2") produce("ITEM3") produce("ITEM4") p1.join() p2.join()
Следует отметить, что все блокировки спрятаны в реализации очереди, поэтому в коде они явным образом не присутствуют.
Пример многопоточной программы
В следующем примере создается два дополнительных потока, которые выводят на стандартный вывод каждый свое:
import threading
def proc(n): print "Процесс", n
p1 = threading.Thread(target=proc, name="t1", args=["1"]) p2 = threading.Thread(target=proc, name="t2", args=["2"]) p1.start() p2.start()
Сначала получается два объекта класса Thread, которые затем и запускаются с различными аргументами. В данном случае в потоках работает одна и та же функция proc(), которой передается один аргумент, заданный в именованном параметре args конструктора класса Thread. Нетрудно догадаться, что метод start() служит для запуска нового потока. Таким образом, в приведенном примере работают три потока: основной и два дополнительных (с именами "t1" и "t2").
Семафоры
Семафоры (их иногда называют семафорами Дийкстры (Dijkstra) по имени их изобретателя) являются более общим механизмом синхронизации потоков, нежели замки. Семафоры могут допустить в критическую область программы сразу несколько потоков. Семафор имеет счетчик запросов, уменьшающийся с каждым вызовом метода acquire() и увеличивающийся при каждом вызове release(). Счетчик не может стать меньше нуля, поэтому в таком состоянии потокам приходится ждать, как и в случае с замками, пока значение счетчика не увеличится.
Конструктор класса threading.Semaphore принимает в качестве (необязательного) аргумента начальное состояние счетчика (по умолчанию оно равно 1, что соответствует замку класса Lock). Методы acquire() и release() действуют аналогично описанным выше одноименным методам у замков.
Семафор может применяться для охраны ограниченного ресурса. Например, с его помощью можно вести пул соединений с базой данных. Пример такого использования семафора (заимствован из документации к Python) дан ниже:
from threading import BoundedSemaphore maxconnections = 5 # Подготовка семафора pool_sema = BoundedSemaphore(value=maxconnections)
# Внутри потока:
pool_sema.acquire() conn = connectdb() # ... использование соединения ... conn.close() pool_sema.release()
Таким образом, применяется не более пяти соединений с базой данных. В примере использован класс threading.BoundedSemaphore. Экземпляры этого класса отличаются от экземпляров класса threading.Semaphore тем, что не дают сделать release() больше, чем сделан acquire().
Еще одним способом коммуникации между
Еще одним способом коммуникации между объектами являются события. Экземпляры класса threading.Event могут быть использованы для передачи информации о наступлении некоторого события от одного потока одному или нескольким другим потокам. Объекты-события имеют внутренний флаг, который может находиться в установленном или сброшенном состоянии. При своем создании флаг события находится в сброшенном состоянии. Если флаг в установленном состоянии, ожидания не происходит: поток, вызвавший метод wait() для ожидания события, просто продолжает свою работу. Ниже приведены методы экземпляров класса threading.Event:
set()Устанавливает внутренний флаг, сигнализирующий о наступлении события. Все ждущие данного события потоки выходят из состояния ожидания.clear()Сбрасывает флаг. Все события, которые вызывают метод wait() этого объекта-события, будут находиться в состоянии ожидания до тех пор, пока флаг сброшен, или по истечении заданного таймаута.isSet()Возвращает состояние флага.wait([timeout])Переводит поток в состояние ожидания, если флаг сброшен, и сразу возвращается, если флаг установлен. Аргумент timeout задает таймаут в секундах, по истечении которого ожидание прекращается, даже если событие не наступило.
Составить пример работы с событиями предлагается в качестве упражнения.
Таймер
Класс threading.Timer представляет действие, которое должно быть выполнено через заданное время. Этот класс является подклассом класса threading.Thread, поэтому запускается также методом start(). Следующий простой пример, печатающий на стандартном выводе Hello, world! поясняет сказанное:
def hello(): print "Hello, world!"
t = Timer(30.0, hello) t.start()
Тупиковая ситуация (deadlock)
Замки применяются для управления доступом к ресурсу, который нельзя использовать совместно. В программе таких ресурсов может быть несколько. При работе с замками важно хорошо продумать, не зайдет ли выполнение программы в тупик (deadlock) из-за того, что двум потокам потребуются одни и те же ресурсы, но ни тот, ни другой не смогут их получить, так как они уже получили замки. Такая ситуация проиллюстрирована в следующем примере:
import threading, time
resource = {'A': threading.Lock(), 'B': threading.Lock()}
def proc(n, rs): for r in rs: print "Процесс %s запрашивает ресурс %s" % (n, r) resource[r].acquire() print "Процесс %s получил ресурс %s" % (n, r) time.sleep(1) print "Процесс %s выполняется" % n for r in rs: resource[r].release() print "Процесс %s закончил выполнение" % n
p1 = threading.Thread(target=proc, name="t1", args=["1", "AB"]) p2 = threading.Thread(target=proc, name="t2", args=["2", "BA"]) p1.start() p2.start() p1.join() p2.join()
В этом примере два потока (t1 и t2) запрашивают замки к одним и тем же ресурсам (A и B), но в разном порядке, отчего получается, что ни у того, ни у другого не хватает ресурсов для дальнейшей работы, и они оба безнадежно повисают, ожидая освобождения нужного ресурса. Благодаря операторам print можно увидеть последовательность событий:
Процесс 1 запрашивает ресурс A Процесс 1 получил ресурс A Процесс 2 запрашивает ресурс B Процесс 2 получил ресурс B Процесс 1 запрашивает ресурс B Процесс 2 запрашивает ресурс A
Существуют методики, позволяющие избежать подобных тупиков, однако их рассмотрение не входит в рамки данной лекции. Можно посоветовать следующие приемы:
построить логику приложения так, чтобы никогда не запрашивать замки к двум ресурсам сразу. Возможно, придется определить составной ресурс. В частности, к данному примеру можно было бы определить замок "AB" для указания эксклюзивного доступа к ресурсам A и B.строго упорядочить все ресурсы (например, по цене) и всегда запрашивать их в определенном порядке (скажем, начиная с более дорогих ресурсов). При этом перед заказом некоторого ресурса поток должен отказаться от заблокированных им более дешевых ресурсов.
Условия
Более сложным механизмом коммуникации между потоками является механизм условий. Условия представляются в виде экземпляров класса threading.Condition и, подобно только что рассмотренным событиям, оповещают потоки об изменении некоторого состояния. Конструктор класса threading.Condition принимает необязательный параметр, задающий замок класса threading.Lock или threading.RLock. По умолчанию создается новый экземпляр замка класса threading.RLock. Методы объекта-условия описаны ниже:
acquire(...)Запрашивает замок. Фактически вызывается одноименный метод принадлежащего объекту-условию объекта-замка.release()Снимает замок. wait([timeout])Переводит поток в режим ожидания. Этот метод может быть вызван только в том случае, если вызывающий его поток получил замок. Метод снимает замок и блокирует поток до появления объявлений, то есть вызовов методов notify() и notifyAll() другими потоками. Необязательный аргумент timeout задает таймаут ожидания в секундах. При выходе из ожидания поток снова запрашивает замок и возвращается из метода wait().notify()Выводит из режима ожидания один из потоков, ожидающих данные условия. Метод можно вызвать, только овладев замком, ассоциированным с условием. Документация предупреждает, что в будущих реализациях модуля из целей оптимизации этот метод будет прерывать ожидание сразу нескольких потоков. Сам по себе метод notify() не приводит к продолжению выполнения ожидавших условия потоков, так как этому препятствует занятый замок. Потоки получают управление только после снятия замка потоком, вызвавшим метод notify().notifyAll()Этот метод аналогичен методу notify(), но прерывает ожидание всех ждущих выполнения условия потоков.
В следующем примере условия используются для оповещения потоков о прибытии новой порции данных (организуется связь производитель - потребитель, producer - consumer):
import threading
cv = threading.Condition()
class Item: """Класс-контейнер для элементов, которые будут потребляться в потоках""" def __init__(self): self._items = [] def is_available(self): return len(self._items) > 0 def get(self): return self._items.pop() def make(self, i): self._items.append(i)
item = Item()
def consume(): """Потребление очередного элемента (с ожиданием его появления)""" cv.acquire() while not item.is_available(): cv.wait() it = item.get() cv.release() return it
def consumer(): while True: print consume()
def produce(i): """Занесение нового элемента в контейнер и оповещение потоков""" cv.acquire() item.make(i) cv.notify() cv.release()
p1 = threading.Thread(target=consumer, name="t1") p1.setDaemon(True) p2 = threading.Thread(target=consumer, name="t2") p2.setDaemon(True) p1.start() p2.start() produce("ITEM1") produce("ITEM2") produce("ITEM3") produce("ITEM4") p1.join() p2.join()
В этом примере условие cv отражает наличие необработанных элементов в контейнере item. Функция produce() "производит" элементы, а consume(), работающая внутри потоков, "потребляет". Стоит отметить, что в приведенном виде программа никогда не закончится, так как имеет бесконечный цикл в потоках, а в главном потоке - ожидание завершения этих потоков. Еще одна особенность - признак демона, установленный с помощью метода setDaemon() объекта-потока до его старта.
Визуализация работы потоков
Следующий пример иллюстрирует параллельность выполнения потоков, используя возможности библиотеки графических примитивов Tkinter (она входит в стандартную поставку Python). Несколько потоков наперегонки увеличивают размеры прямоугольника некоторого цвета. Цветом победившего потока окрашивается кнопка Go:
import threading, time, sys from Tkinter import Tk, Canvas, Button, LEFT, RIGHT, NORMAL, DISABLED
global champion
# Задается дистанция, цвет полосок и другие параметры distance = 300 colors = ["Red","Orange","Yellow","Green","Blue","DarkBlue","Violet"] nrunners = len(colors) # количество дополнительных потоков positions = [0] * nrunners # список текущих позиций h, h2 = 20, 10 # параметры высоты полосок
def run(n): """Программа бега n-го участника (потока)""" global champion while 1: for i in range(10000): # интенсивные вычисления pass graph_lock.acquire() positions[n] += 1 # передвижение на шаг if positions[n] == distance: # если уже финиш if champion is None: # и чемпион еще не определен, champion = colors[n] # назначается чемпион graph_lock.release() break graph_lock.release()
def ready_steady_go(): """Инициализация начальных позиций и запуск потоков""" graph_lock.acquire() for i in range(nrunners): positions[i] = 0 threading.Thread(target=run, args=[i,]).start() graph_lock.release()
def update_positions(): """Обновление позиций""" graph_lock.acquire() for n in range(nrunners): c.coords(rects[n], 0, n*h, positions[n], n*h+h2) tk.update_idletasks() # прорисовка изменений graph_lock.release()
def quit(): """Выход из программы""" tk.quit() sys.exit(0)
# Прорисовка окна, основы для прямоугольников и самих прямоугольников, # кнопок для пуска и выхода tk = Tk() tk.title("Соревнование потоков") c = Canvas(tk, width=distance, height=nrunners*h, bg="White") c.pack() rects = [c.create_rectangle(0, i*h, 0, i*h+h2, fill=colors[i]) for i in range(nrunners)] go_b = Button(text="Go", command=tk.quit) go_b.pack(side=LEFT) quit_b = Button(text="Quit", command=quit) quit_b.pack(side=RIGHT)
# Замок, регулирующий доступ к функции пакета Tk graph_lock = threading.Lock()
# Цикл проведения соревнований while 1: go_b.config(state=NORMAL), quit_b.config(state=NORMAL) tk.mainloop() # Ожидание нажатия клавиш champion = None ready_steady_go() go_b.config(state=DISABLED), quit_b.config(state=DISABLED) # Главный поток ждет финиша всех участников while sum(positions) < distance*nrunners: update_positions() update_positions() go_b.config(bg=champion) # Кнопка окрашивается в цвет победителя tk.update_idletasks()
Примечание:
Эта программа использует некоторые возможности языка Python 2.3 (встроенную функцию sum() и списковые включения), поэтому для ее выполнения нужен Python версии не меньше 2.3.
Навыки параллельного программирования необходимы любому
Навыки параллельного программирования необходимы любому профессиональному программисту. Одним из вариантов организации (псевдо) параллельного программирования является многопоточное программирование (другой вариант, более свойственный Unix-системам - многопроцессное программирование - здесь не рассматривается). В обычной (однопоточной) программе действует всего один поток управления, а в многопоточной одновременно могут работать несколько потоков.
Параллельное программирование требует тщательной отработки взаимодействия между потоками управления. Некоторые участки кода необходимо ограждать от одновременного использования двумя различными потоками, дабы не нарушить целостность изменяемых структур данных или логику работы с внешними ресурсами. Для ограждения участков кода используются замки и семафоры.
Стандартная библиотека Python предоставляет довольно неплохой набор возможностей для многопоточного программирования в модулях threading и thread, а также некоторые полезные вспомогательные модули (например, Queue).
Замки
Простейший замок может быть реализован на основе класса Lock модуля threading. Замок имеет два состояния: он может быть или открыт, или заперт. В последнем случае им владеет некоторый поток. Объект класса Lock имеет следующие методы:
acquire([blocking=True])Делает запрос на запирание замка. Если параметр blocking не указан или является истиной, то поток будет ожидать освобождения замка. Если параметр не был задан, метод не возвратит значения. Если blocking был задан и истинен, метод возвратит True (после успешного овладения замком). Если блокировка не требуется (то есть задан blocking=False), метод вернет True, если замок не был заперт и им успешно овладел данный поток. В противном случае будет возвращено False.release()Запрос на отпирание замка.locked()Возвращает текущее состояние замка (True - заперт, False - открыт). Следует иметь в виду, что даже если состояние замка только что проверено, это не означает, что он сохранит это состояние до следующей команды.
Имеется еще один вариант замка - threading.RLock, который отличается от threading.Lock тем, что некоторый поток может запрашивать его запирание много раз. Отпирание такого замка должно происходить столько же раз, сколько было запираний. Это может быть полезно, например, внутри рекурсивных функций.
Графическое приложение на Tkinter
Теперь следует рассмотреть небольшое приложение, написанное с использованием Tkinter. В этом приложении будет загружен файл с графическим изображением. Приложение будет иметь простейшее меню File с пунктами Open и Exit, а также виджет Canvas, на котором и будут демонстрироваться изображения (опять потребуется пакет PIL):
from Tkinter import * import Image, ImageTk, tkFileDialog global img, imgobj
def show(): global img, imgobj # Запрос на имя файла filename = tkFileDialog.askopenfilename() if filename != (): # Если имя файла было задано пользователем # рисуется изображение из файла src_img = Image.open(filename) img = ImageTk.PhotoImage(src_img) # конфигурируется изображение на рисунке c.itemconfigure(imgobj, image=img, anchor="nw")
tk = Tk() main_menu = Menu(tk) # формируется меню tk.config(menu=main_menu) # меню добавляется к окну file_menu = Menu(main_menu) # создается подменю main_menu.add_cascade(label="File", menu=file_menu) # Заполняется меню File file_menu.add_command(label="Open", command=show) file_menu.add_separator() # черта для отделения пунктов меню file_menu.add_command(label="Exit", command=tk.destroy)
c = Canvas(tk, width=300, height=300, bg="white") # готовим объект-изображение на рисунке imgobj = c.create_image(0, 0) c.pack()
tk.mainloop()
Приложение (с загруженной картинкой) будет выглядеть так:

Стоит отметить, что здесь пришлось применить две глобальные переменные. Это не очень хорошо. Существует другой подход, когда приложение создается на основе окна верхнего уровня. Таким образом, само приложение становится особым виджетом. Переделанная программа представлена ниже:
from Tkinter import * import Image, ImageTk, tkFileDialog
class App(Tk): def __init__(self): Tk.__init__(self) main_menu = Menu(self) self.config(menu=main_menu) file_menu = Menu(main_menu) main_menu.add_cascade(label="File", menu=file_menu) file_menu.add_command(label="Open", command=self.show_img) file_menu.add_separator() file_menu.add_command(label="Exit", command=self.destroy)
self.c = Canvas(self, width=300, height=300, bg="white") self.imgobj = self.c.create_image(0, 0) self.c.pack()
def show_img(self): filename = tkFileDialog.askopenfilename() if filename != (): src_img = Image.open(filename) self.img = ImageTk.PhotoImage(src_img) self.c.itemconfigure(self.imgobj, image=self.img, anchor="nw")
app = App() app.mainloop()
В объекте заключена информация, которая до этого была глобальной со всеми следующими из этого ограничениями. Можно пойти дальше и выделить в отдельный метод настройку меню (если приложение будет динамически изменять меню, объекты-меню тоже могут быть сохранены в приложении).
Примечание:
На некоторых системах новые версии Python плохо работают с национальными кодировками, в частности, с кодировками для кириллицы. Это связано с переходом на Unicode Tcl/Tk. Проблем можно избежать, если использовать кодировку UTF-8 в строках, которые должны выводиться в виджетах.
Изображения в Tkinter
Средствами Tkinter можно выводить не только текст, примитивные формы (с помощью виджета Canvas), но и растровые изображения. Следующий пример демонстрирует вывод иконки с растровым изображением (для этого примера нужно предварительно установить пакет Python Imaging Library, PIL):
import Tkinter, Image, ImageTk
FILENAME = "lena.jpg" # файл с графическим изображением
tk = Tkinter.Tk() c = Tkinter.Canvas(tk, width=128, height=128) src_img = Image.open(FILENAME)
img = ImageTk.PhotoImage(src_img) c.create_image(0, 0, image=img, anchor="nw") c.pack() Tkinter.Label(tk, text=FILENAME).pack()
tk.mainloop()
В результате получается:

Здесь использован виджет-рисунок (Canvas). С помощью функций из пакетов Image и ImageTk из PIL получается объект-изображение, подходящее для включения в рисунок Tkinter. Свойство anchor задает угол, который привязывается к координатам (0, 0) в рисунке. В данном примере это северо-западный угол (NW - North-West). Другие возможности: n (север), w (запад), s (юг), e (восток), ne, sw, se и с (центр).
В следующем примере показаны графические примитивы, которые можно использовать на рисунке (приведенные комментарии объясняют свойства графических объектов внутри виджета-рисунка):
from Tkinter import *
tk = Tk() # Рисунок 300x300 пикселей, фон - белый c = Canvas(tk, width=300, height=300, bg="white")
c.create_arc((5, 5, 50, 50), style=PIESLICE) # Сектор ("кусок пирога") c.create_arc((55, 5, 100, 50), style=ARC) # Дуга c.create_arc((105, 5, 150, 50), style=CHORD, # Сегмент start=0, extent=150, fill="blue") # от 0 до 150 градусов # Ломаная со стрелкой на конце c.create_line([(5, 55), (55, 55), (30, 95)], arrow=LAST) # Кривая (сглаженная ломаная) c.create_line([(105, 55), (155, 55), (130, 95)], smooth=1) # Многоугольник зеленого цвета c.create_polygon([(205, 55), (255, 55), (230, 95)], fill="green") # Овал c.create_oval((5, 105, 50, 120), ) # Прямоугольник красного цвета с большой серой границей c.create_rectangle((105, 105, 150, 130), fill="red", outline="grey", width="5") # Текст c.create_text((5, 205), text=" Hello", anchor="nw") # Эта точка визуально обозначает угол привязки c.create_oval((5, 205, 6, 206), outline="red") # Текст с заданным выравниванием c.create_text((105, 205), text="Hello,\nmy friend!", justify=LEFT, anchor="c") c.create_oval((105, 205, 106, 206), outline="red") # Еще один вариант c.create_text((205, 205), text="Hello,\nmy friend!", justify=CENTER, anchor="se") c.create_oval((205, 205, 206, 206), outline="red")
c.pack() tk.mainloop()
В результате работы этой программы на экране появится окно:
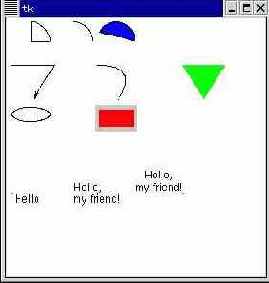
Следует заметить, что методы create_* создают объекты, свойства которых можно менять в дальнейшем: переместить в другое место, перекрасить, удалить, изменить порядок и т.д. В следующем примере можно нарисовать кружок, меняющий цвет по щелчку мыши:
from Tkinter import * from random import choice
colors = "Red Orange Yellow Green LightBlue Blue Violet".split() R = 10
tk = Tk() c = Canvas(tk, bg="White", width="4i", height=300, relief=SUNKEN) c.pack(expand=1, fill=BOTH)
def change_ball(event): c.coords(CURRENT, (event.x-R, event.y-R, event.x+R, event.y+R)) c.itemconfigure(CURRENT, fill=choice(colors))
oval = c.create_oval((100-R, 100-R, 100+R, 100+R), fill="Black") c.tag_bind(oval, "<1>", change_ball) tk.mainloop()
Здесь нарисован кружок радиуса R , с ним связана функция change_ball() по нажатию кнопки мыши. В указанной функции заданы новые координаты кружка (его центр расположен в месте щелчка мыши) и затем изменен цвет случайным образом методом itemconfigure(). Тег CURRENT в Tkinter использован для указания объекта, который принял событие.
Классы виджетов
Для построения графического интерфейса в библиотеке Tk отобраны следующие классы виджетов (в алфавитном порядке):
Button (Кнопка) Простая кнопка для вызова некоторых действий (выполнения определенной команды).Canvas (Рисунок) Основа для вывода графических примитивов.Checkbutton (Флажок) Кнопка, которая умеет переключаться между двумя состояниями при нажатии на нее.Entry (Поле ввода) Горизонтальное поле, в которое можно ввести строку текста.Frame (Рамка) Виджет, который содержит в себе другие визуальные компоненты.Label (Надпись) Виджет может показывать текст или графическое изображение.Listbox (Список) Прямоугольная рамка со списком, из которого пользователь может выделить один или несколько элементов.Menu (Меню) Элемент, с помощью которого можно создавать всплывающие (popup) и ниспадающие (pulldown) меню.Menubutton (Кнопка-меню) Кнопка с ниспадающим меню.Message (Сообщение) Аналогично надписи, но позволяет заворачивать длинные строки и менять размер по требованию менеджера расположения.Radiobutton (Селекторная кнопка) Кнопка для представления одного из альтернативных значений. Такие кнопки, как правило, действует в группе. При нажатии на одну из них кнопка группы, выбранная ранее, "отскакивает".Scale (Шкала) Служит для задания числового значения путем перемещения движка в определенном диапазоне.Scrollbar (Полоса прокрутки) Полоса прокрутки служит для отображения величины прокрутки в других виджетах. Может быть как вертикальной, так и горизонтальной.Text (Форматированный текст) Этот прямоугольный виджет позволяет редактировать и форматировать текст с использованием различных стилей, внедрять в текст рисунки и даже окна.Toplevel (Окно верхнего уровня) Показывается как отдельное окно и содержит внутри другие виджеты.
Все эти классы не имеют отношений наследования друг с другом - они равноправны. Этот набор достаточен для построения интерфейса в большинстве случаев.
Менеджеры расположения
Следующий пример достаточно нагляден, чтобы понять принципы работы менеджеров расположения, имеющихся в Tk. В трех рамках можно применить различные менеджеры: pack, grid и place:
from Tkinter import * tk = Tk()
# Создаем три рамки frames = {} b = {} for fn in 1, 2, 3: f = Frame(tk, width=100, height=200, bg="White") f.pack(side=LEFT, fill=BOTH) frames[fn] = f for bn in 1, 2, 3, 4: # Создаются кнопки для каждой из рамок b[fn, bn] = Button(frames[fn], text="%s.%s" % (fn, bn))
# Первая рамка: # Сначала две кнопки прикрепляются к левому краю b[1, 1].pack(side=LEFT, fill=BOTH, expand=1) b[1, 2].pack(side=LEFT, fill=BOTH, expand=1) # Еще две - к нижнему b[1, 3].pack(side=BOTTOM, fill=Y) b[1, 4].pack(side=BOTTOM, fill=BOTH)
# Вторая рамка: # Две кнопки сверху b[2, 1].grid(row=0, column=0, sticky=NW+SE) b[2, 2].grid(row=0, column=1, sticky=NW+SE) # и одна на две колонки в низу b[2, 3].grid(row=1, column=0, columnspan=2, sticky=NW+SE)
# Третья рамка: # Кнопки высотой и шириной в 40% рамки, якорь в левом верхнем углу. # Координаты якоря 1/10 от ширины и высоты рамки b[3, 1].place(relx=0.1, rely=0.1, relwidth=0.4, relheight=0.4, anchor=NW) # Кнопка строго по центру. Якорь в центре кнопки b[3, 2].place(relx=0.5, rely=0.5, relwidth=0.4, relheight=0.4, anchor=CENTER) # Якорь по центру кнопки. Координаты якоря 9/10 от ширины и высоты рамки b[3, 3].place(relx=0.9, rely=0.9, relwidth=0.4, relheight=0.4, anchor=CENTER)
tk.mainloop()
Результат следующий:
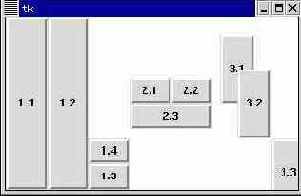
Менеджер pack просто заполняет внутреннее пространство на основании предпочтения того или иного края, необходимости заполнить все измерение. В некоторых случаях ему приходится менять размеры подчиненных виджетов. Этот менеджер стоит использовать только для достаточно простых схем расположения виджетов.
Менеджер grid помещает виджеты в клетки сетки (это очень похоже на способ верстки таблиц в HTML). Каждому располагаемому виджету даются координаты в одной из ячеек сетки (row - строка, column - столбец), а также, если нужно, столько последующих ячеек (в строках ниже или в столбцах правее) сколько он может занять (свойства rowspan или columnspan). Это самый гибкий из всех менеджеров.
Менеджер place позволяет располагать виджеты по произвольным координатам и с произвольными размерами подчиненных виджетов. Размеры и координаты могут быть заданы в долях от размера виджета-хозяина.
Непосредственно внутри одного виджета нельзя использовать более одного менеджера расположения: менеджеры могут наложить противоречащие ограничения на вложенные виджеты и внутренние виджеты просто не смогут быть расположены.
О графическом интерфейсе
Почти все современные графические интерфейсы общего назначения строятся по модели WIMP - Window, Icon, Menu, Pointer (окно, иконка, меню, указатель). Внутри окон рисуются элементы графического интерфейса, которые для краткости будут называться виджетами (widget - штучка). Меню могут располагаться в различных частях окна, но их поведение достаточно однотипно: они служат для выбора действия из набора предопределенных действий. Пользователь графического интерфейса "объясняет" компьютерной программе требуемые действия с помощью указателя. Обычно указателем служит курсор мыши или джойстика, однако есть и другие "указательные" устройства. С помощью иконок графический интерфейс приобретает независимость от языка и в некоторых случаях позволяет быстрее ориентироваться в интерфейсе.
Основной задачей графического интерфейса является упрощение коммуникации между пользователем и компьютером. Об этом следует постоянно помнить при проектировании интерфейса. Применение имеющихся в наличии у программиста (или дизайнера) средств при создании графического интерфейса нужно свести до минимума, выбирая наиболее удобные пользователю виджеты в каждом конкретном случае. Кроме того, полезно следовать принципу наименьшего удивления: из формы интерфейса должно быть понятно его поведение. Плохо продуманный интерфейс портит ощущения пользователя от программы, даже если за фасадом интерфейса скрывается эффективный алгоритм. Интерфейс должен быть удобен для типичных действий пользователя. Для многих приложений такие действия выделены в отдельные серии экранов, называемые "мастерами" (wizards). Однако если приложение - скорее конструктор, из которого пользователь может строить нужные ему решения, типичным действием является именно построение решения. Определить типичные действия не всегда легко, поэтому компромиссом может быть гибрид, в котором есть "мастера" и хорошие возможности для собственных построений. Тем не менее, графический интерфейс не является самым эффективным интерфейсом во всех случаях. Для многих предметных областей решение проще выразить с помощью деклараций на некотором формальном языке или алгоритма на сценарном языке.
Обзор графических библиотек
Строить графический интерфейс пользователя (GUI, Graphical User Interface) для программ на языке Python можно при помощи соответствующих библиотек компонентов графического интерфейса или, используя кальку с английского, библиотек виджетов.
Следующий список далеко не полон, но отражает многообразие существующих решений:
Tkinter Многоплатформенный пакет имеет хорошее управление расположением компонентов. Интерфейс выглядит одинаково на различных платформах (Unix, Windows, Macintosh). Входит в стандартную поставку Python. В качестве документации можно использовать руководство "An Introduction to Tkinter" ("Введение в Tkinter"), написанное Фредриком Лундом: http://www.pythonware.com/library/tkinter/introduction/wxPython Построен на многоплатформной библиотеке wxWidgets (раньше называлась wxWindows). Выглядит родным для всех платформ, активно совершенствуется, осуществлена поддержка GL. Имеется для всех основных платформ. Возможно, займет место Tkinter в будущих версиях Python. Сайт: http://www.wxpython.org/PyGTK Набор визуальных компонентов для GTK+ и Gnome. Только для платформы GTK.PyQT/PyKDE Хорошие пакеты для тех, кто использует Qt (под UNIX или Windows) или KDE.Pythonwin Построен вокруг MFC, поставляется вместе с оболочкой в пакете win32all; только для Windows.pyFLTK Аналог Xforms, поддержка OpenGL. Имеется для платформ Windows и Unix. Сайт: http://pyfltk.sourceforge.net/AWT, JFC, Swing Поставляется вместе с Jython, а для Jython доступны средства, которые использует Java. Поддерживает платформу Java.anygui Независимый от нижележащей платформы пакет для построения графического интерфейса для программ на Python. Сайт: http://anygui.sourceforge.net/PythonCard Построитель графического интерфейса, сходный по идеологии с HyperCard/MetaCard. Разработан на базе wxPython. Сайт: http://pythoncard.sourceforge.net/
Список актуальных ссылок на различные графические библиотеки, доступные из Python, можно найти по следующему адресу: http://phaseit.net/claird/comp.lang.python/python_GUI.html
Библиотеки могут быть многоуровневыми. Например, PythonCard использует wxPython, который, скажем, на платформе Linux базируется на многоплатформной GUI-библиотеке wxWindows, которая, в свою очередь, базируется на GTK+ или на Motif, а те - тоже используют для вывода X Window. Кстати, для Motif в Python имеются свои привязки.
В лекции будет рассматриваться пакет Tkinter, который по сути является оберткой для Tcl/Tk - известного графического пакета для сценарного языка Tcl. На примере этого пакета легко изучить основные принципы построения графического интерфейса пользователя.
Основы Tk
Основная черта любой программы с графическим интерфейсом - интерактивность. Программа не просто что-то считает (в пакетном режиме) от начала своего запуска до конца: ее действия зависят от вмешательства пользователя. Фактически, графическое приложение выполняет бесконечный цикл обработки событий. Программа, реализующая графический интерфейс, событийно-ориентирована. Она ждет от интерфейса событий, которые и обрабатывает сообразно своему внутреннему состоянию.
Эти события возникают в элементах графического интерфейса (виджетах) и обрабатываются прикрепленными к этим виджетам обработчиками. Сами виджеты имеют многочисленные свойства (цвет, размер, расположение), выстраиваются в иерархию принадлежности (один виджет может быть хозяином другого), имеют методы для доступа к своему состоянию.
Расположением виджетов (внутри других виджетов) ведают так называемые менеджеры расположения. Виджет устанавливается на место по правилам менеджера расположения. Эти правила могут определять не только координаты виджета, но и его размеры. В Tk имеются три типа менеджеров расположения: простой упаковщик (pack), сетка (grid) и произвольное расположение (place).
Но этого для работы графической программы недостаточно. Дело в том, что некоторые виджеты в графической программе должны быть взаимосвязаны определенным образом. Например, полоска прокрутки может быть взаимосвязана с текстовым виджетом: при использовании полоски текст в виджете должен двигаться, и наоборот, при перемещении по тексту полоска должна показывать текущее положение. Для связи между виджетами в Tk используются переменные, через которые виджеты и передают друг другу параметры.
В системе современного графического интерфейса
В системе современного графического интерфейса имеется возможность отслеживать различные события, связанные с клавиатурой и мышью, и происходящие на "территории" того или иного виджета. В Tk события описываются в виде текстовой строки - шаблона события, состоящего из трех элементов (модификаторы, тип события и детализация события).
| Activate | Активизация окна |
| ButtonPress | Нажатие кнопки мыши |
| ButtonRelease | Отжатие кнопки мыши |
| Deactivate | Деактивация окна |
| Destroy | Закрытие окна |
| Enter | Вхождение курсора в пределы виджета |
| FocusIn | Получение фокуса окном |
| FocusOut | Потеря фокуса окном |
| KeyPress | Нажатие клавиши на клавиатуре |
| KeyRelease | Отжатие клавиши на клавиатуре |
| Leave | Выход курсора за пределы виджета |
| Motion | Движение мыши в пределах виджета |
| MouseWheel | Прокрутка колесика мыши |
| Reparent | Изменение родителя окна |
| Visibility | Изменение видимости окна |
Примеры описаний событий строками и некоторые названия клавиш приведены ниже:
"<ButtonPress-3>" или просто "<3>" - щелчок правой кнопки мыши (то есть, третьей, если считать на трехкнопочной мыши слева-направо). "<Shift-Double-Button-1>" - двойной щелчок мышью (левой кнопкой) с нажатой кнопкой Shift. В качестве модификаторов могут быть использованы следующие (список неполный):
Control, Shift, Lock, Button1-Button5 или B1-B5, Meta, Alt, Double, Triple.
Просто символ обозначает событие - нажатие клавиши. Например, "k" - тоже, что "<KeyPress-k>". Для неалфавитно-цифровых клавиш есть специальные названия:
Cancel, BackSpace, Tab, Return, Shift_L, Control_L, Alt_L, Pause, Caps_Lock, Escape, Prior, Next, End, Home, Left, Up, Right, Down, Print, Insert, Delete, F1, F2, F3, F4, F5, F6, F7, F8, F9, F10, F11, F12, Num_Lock, Scroll_Lock, space, less
Здесь <space> обозначает пробел, а <less> - знак меньше. <Left>, <Right>, <Up>, <Down> - стрелки. <Prior>, <Next> - это PageUp и PageDown. Остальные клавиши более или менее соответствуют надписям на стандартной клавиатуре.
Примечание:
Следует заметить, что Shift_L, в отличие от Shift, нельзя использовать как модификатор.
В конкретной среде комбинации, означающие что-то особенное в системе, могут не дойти до графического приложения. Например, известный всем Ctrl-Alt-Del.
Следующая программа позволяет печатать направляемые виджету события, в частности - keysym, а также анализировать, как различные клавиши можно представить в шаблоне события:
from Tkinter import * tk = Tk() # основное окно приложения txt = Text(tk) # текстовый виджет, принадлежащий окну tk txt.pack() # располагается менеджером pack
# функция обработки события def event_info(event): txt.delete("1.0", END) # удаляется с начала до конца текста for k in dir(event): # цикл по атрибутам события if k[0] != "_": # берутся только неслужебные атрибуты # готовится описание атрибута события ev = "%15s: %s\n" % (k, repr(getattr(event, k))) txt.insert(END, ev) # добавляется в конец текста
# привязывается виджету txt функция event_info для обработки событий, # соответствующих шаблону <KeyPress> txt.bind("<KeyPress>", event_info) tk.mainloop() # главный цикл обработки событий
При нажатии клавиши Esc в окне можно увидеть примерно следующее:
char: '\x1b' delta: 9 height: 0 keycode: 9 keysym: 'Escape' keysym_num: 65307 num: 9 send_event: False serial: 159 state: 0 time: -1072960858 type: '2' widget: <Tkinter.Text instance at 0x401e268c> width: 0 x: 83 x_root: 448 y: 44 y_root: 306
Следует объяснить некоторые из этих атрибутов:
char Нажатый символ (для некоторых событий - ??)height, width Высота и ширина.focus Был ли в момент события фокус у окна?keycode Код символа (скан-код клавиатуры).keysym Символическое имя клавиши.serial Серийный номер события. Увеличивается по мере возникновения событий.time Время возникновения события. Все время увеличивается.widget Виджет, в котором возникло событие.x, y Координаты указателя в виджете во время события.x_root, y_root Координаты указателя на экране во время события.
В принципе, совсем необязательно, чтобы события обрабатывал тот же виджет, который их первично принял. Например, можно перенаправить все события внутри подчиненных виджетов на данный виджет с помощью метода grab_set() (grab_release() освобождает виджет от этой обязанности). В Tk существуют и другие возможности управления событиями, которые можно изучить по документации.
Создание и конфигурирование виджета
Создание виджета происходит вызовом конструктора соответствующего класса. Вызов конструктора имеет следующий синтаксис:
Widget([master[, option=value, ...]])
Здесь Widget - класс виджета, master - виджет-хозяин, option и value - конфигурационная опция и ее значение (таких пар может быть несколько).
Каждый виджет имеет свойства, которые можно устанавливать (конфигурировать) с помощью методов config() (или configure()) и читать с помощью методов, подобных методам работы со словарями. Ниже приведен возможный синтаксис для работы со свойствами:
widget.config(option=value, ...) widget["option"] = value value = widget["option"] widget.keys()
В случае, когда имя свойства совпадает с ключевым словом языка Python, принято использовать после имени одиночное подчеркивание. Так, свойство class нужно задавать как class_, а to как to_.
Изменять конфигурацию виджета можно в любой момент. Это изменение прорисуется на экране по возвращении в цикл обработки событий или при явном вызове update_idletasks().
Следующий пример показывает окно с двумя виджетами внутри - полем ввода и надписью. С помощью переменной надпись напрямую связана с полем ввода. Этот пример нарочно использует очень много свойств, чтобы продемонстрировать возможности по конфигурированию:
from Tkinter import * tk = Tk() tv = StringVar() Label(tk, textvariable=tv, relief="groove", borderwidth=3, font=("Courier", 20, "bold"), justify=LEFT, width=50, padx=10, pady=20, takefocus=False, ).pack() Entry(tk, textvariable=tv, takefocus=True, ).pack() tv.set("123") tk.mainloop()
В результате на экране можно увидеть:
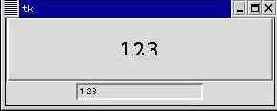
Виджеты конфигурируются прямо при создании. Более того, виджеты не связываются с именами, их только располагают внутри виджета-окна. В данном примере использованы свойства textvariable (текстовая переменная), relief (рельеф), borderwidth (ширина границы), justify (выравнивание), width (ширина, в знакоместах), padx и pady (прослойка в пикселях между содержимым и границами виджета), takefocus (возможность принять фокус при нажатии клавиши Tab), font (шрифт, один из способов его задания).
Эти свойства достаточно типичны для многих виджетов, хотя иногда единицы измерения могут отличаться, например, для виджета Canvas ширина задается в пикселях, а не в знакоместах.
В следующем примере демонстрируются возможности по назначению цветов фону, переднему плану (тексту), выделению виджета (подсветка границы) в активном состоянии и при отсутствии фокуса:
from Tkinter import * tk = Tk() tv = StringVar() Entry(tk, textvariable=tv, takefocus=True, borderwidth=10, ).pack() mycolor1 = "#%02X%02X%02X" % (200, 200, 20) Entry(tk, textvariable=tv, takefocus=True, borderwidth=10, foreground=mycolor1, # fg, текст виджета background="#0000FF", # bg, фон виджета highlightcolor='green', # подсветка при фокусе highlightbackground='red', # подсветка без фокуса ).pack() tv.set("123") tk.mainloop()
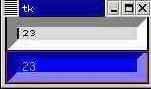
При желании можно задать стилевые опции для всех виджетов сразу: с помощью метода tk_setPalette(). Помимо использованных выше свойств в этом методе можно использовать selectForeground и selectBackground (передний план и фон выделения), selectColor (цвет в выбранном состоянии, например, у Checkbutton), insertBackground (цвет точки вставки) и некоторые другие.
Примечание:
Получить значение из поля ввода можно и при помощи метода get(). Например, если назвать объект класса Entry именем e, получить значение можно так: e.get(). Правда, этот метод не обладает той же гибкостью, что метод get() экземпляров класса для форматированного текста Text: можно взять только все значение целиком.
Список актуальных ссылок на различные графические библиотеки можно найти по следующему адресу:
http://phaseit.net/claird/comp.lang.python/python_GUI.html
Виджет форматированного текста
Для того чтобы показать работу с нетривиальным виджетом, можно взять виджет ScrolledText из одноименного модуля Python. Этот виджет аналогичен рамке с форматированным текстом и вертикальной полосой прокрутки:
from Tkinter import * from ScrolledText import ScrolledText
tk = Tk() # окно верхнего уровня txt = ScrolledText(tk) # виджет текста с прокруткой txt.pack() # виджет размещается
for x in range(1, 1024): # виджет наполняется текстовым содержимым txt.insert(END, str(2L**x)+"\n")
tk.mainloop()
Теперь следует рассмотреть методы и свойства виджета с форматированным текстом более подробно.
Для навигации в тексте в Tk предусмотрены специальные индексы. Индексы вроде 1.0 и END уже встречались - это начало текста (первая строка, нулевой символ) и его конец. (В Tk строки нумеруются с единицы, а символы строки - с нуля). Более полный список индексов:
L.C Здесь L - номер строки, а C - номер символа в строке.INSERT Точка вставки.CURRENT Символ, ближайший к курсору мыши.END Позиция сразу за последним символом в текстеM.first, M.last Индексы начала и конца помеченного тегом M участка текста.SEL_FIRST, SEL_LAST Индексы начала и конца выделенного текста.M Пользователь может определять свои именованные позиции в тексте (аналогично END, INSERT или CURRENT). При редактировании текста маркеры будут сдвигаться с заданными для них правилами.@x,y Символ текста, ближайший к точке с координатами x, y.
Следующий пример показывает, как снабдить форматированный текст гипертекстовыми возможностями:
from Tkinter import * import urllib tk = Tk() txt = Text(tk, width=64) # поле с текстом txt.grid(row=0, column=0, rowspan=2) addr=Text(tk, background="White", width=64, height=1) # поле адреса addr.grid(row=0, column=1) page=Text(tk, background="White", width=64) # поле с html-кодом page.grid(row=1, column=1)
def fetch_url(event): click_point = "@%s,%s" % (event.x, event.y) trs = txt.tag_ranges("href") # список областей текста, отмеченных как href url = "" # определяется, на какой участок пришелся щелчок мыши, и берется # соответствующий ему URL for i in range(0, len(trs), 2): if txt.compare(trs[i], "<=", click_point) and \ txt.compare(click_point, "<=", trs[i+1]): url = txt.get(trs[i], trs[i+1]) html_doc = urllib.urlopen(url).read() addr.delete("1.0", END) addr.insert("1.0", url) # URL помещается в поле адреса page.delete("1.0", END) page.insert("1.0", html_doc) # показывается HTML-документ
textfrags = ["Python main site: ", "http://www.python.org", "\nJython site: ", "http://www.jython.org", "\nThat is all!"] for frag in textfrags: if frag.startswith("http:"): txt.insert(END, frag, "href") # URL помещается в текст с меткой href else: txt.insert(END, frag) # фрагмент помещается в текст
# ссылки отмечаются подчеркиванием и синим цветом txt.tag_config("href", foreground="Blue", underline=1) # при щелчке мыши на тексте, отмеченном как "href", # следует вызывать fetch_url() txt.tag_bind("href", "<1>", fetch_url)
tk.mainloop() # запускается цикл событий
В результате (после нажатия на гиперссылку) можно увидеть примерно следующее:
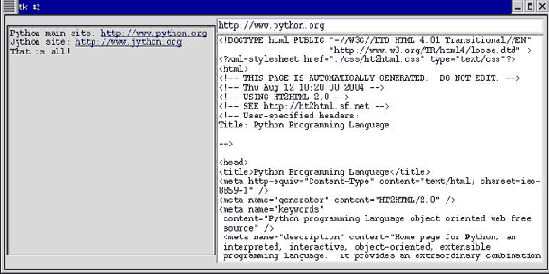
Для придания некоторым участкам текста особых свойств необходимо их отметить тегом. В данном случае URL отмечается тегом href. Позднее с помощью метода tag_config() задаются свойства отображения текста, отмеченного таким тегом. Методом tag_bind() привязывается некоторое событие (щелчок мыши) с вызовом заданной функции (fetch_url()).
В самой функции fetch_url()нужно в начале определить, на какой именно участок текста пришелся щелчок мыши. Для этого с помощью метода tag_ranges() получаются все интервалы, которые отмечены как href. Для определения конкретного URL проводятся сравнения (методом compare()) точки щелчка мышью с каждым из интервалов. Так находится интервал, на который попал щелчок, и с помощью метода get()получается текстовое значение найденного интервала. Найдя URL, его в поле записываются адреса, и получается HTML-код, соответствующий URL.
Этот пример показывает основные принципы работы с форматированным текстом. Примененными методами арсенал виджета не исчерпывается. О других методах и свойствах можно узнать из документации.
В этой лекции было дано
В этой лекции было дано представление о (невизуальном) программировании графического интерфейса для Python на примере пакета Tkinter. Программа с графическим интерфейсом - событийно-управляемая программа, проводящая время в цикле обработки событий. События могут быть вызваны функционированием графического интерфейса или другими причинами (например, по таймеру). Обычно события возникают в виджетах и некоторые из них должны обрабатываться приложением. В Tkinter событие представлено отдельным объектом, из атрибутов которого можно установить, каково было положение указателя (курсора мыши), в каком виджете произошло событие и т.п.
Здесь были рассмотрены классы элементов интерфейса (виджеты), их свойства и методы. Виджеты имеют большое количество свойств и методов. Некоторые свойства и методы достаточно универсальны (их имеют все или почти все виджеты), другие же специфичны для конкретного класса виджетов. Графический пакет Python Imaging Library (PIL) предоставляет класс объекта для расположения в виджете-рисунке растрового графического изображения.
Виджеты располагаются внутри другого виджета (например, рамки) в соответствии с набором правил. Этот набор правил реализуют менеджеры расположения, которых в Tkinter три: pack, grid и place.
Приложение с графическим интерфейсом можно построить на базе окна верхнего уровня, простым наследованием. Этот подход позволяет инкапсулировать информацию, которую в противном случае пришлось бы делать глобальной.
Нужно отметить, что для построения интерфейса можно использовать не только чистый Tkinter. Например, в Python доступны модули ScrolledText и Tix, пополняющие набор виджетов. Кроме того, можно найти пакеты для специальных виджетов (например, для отображения дерева).
Построение графического интерфейса невизуальными способами - не такая сложная задача, если использовать Tkinter. Этот пакет входит в стандартную поставку Python и потому может использоваться почти везде, где установлен Python.
C API
Доступные из языка Python модули расширяются за счет модулей расширения (extension modules). Модули расширения можно писать на языке C или C++ и вызывать из программ на Python. В этой лекции речь пойдет о реализации Python, называемой CPython(Jython, реализация Python на платформе Java не будет рассматриваться).
Сама необходимость использования языка C может возникнуть, если реализуемый алгоритм, будучи запрограммирован на Python, работает медленно. Например, высокопроизводительные операции с массивами модуля Numeric (о котором говорилось в одной из предыдущих лекций) написаны на языке C. Модули расширения позволяют объединить эффективность порождаемого компилятором C/C++ кода c удобством и гибкостью интерпретатора Python. Необходимые сведения для создания модулей расширения для Python даны в исчерпывающем объеме в стандартной документации, а именно в документе "Python/C API Reference Manual" (справочное руководство по "Python/C API"). Здесь будут рассмотрены лишь основные принципы построения модуля расширения, без детальных подробностей об API. Стоит заметить, что возможности Python равно доступны и в C++, просто они выражены в C-декларациях, которые можно использовать в C++.
Все необходимые для модуля расширения определения находятся в заголовочном файле Python.h, который должен находится где-то на пути заголовочных файлов компилятора C/C++. Следует пользоваться теми же версиями библиотек, с которыми был откомпилирован Python. Желательно, и той же маркой компилятора C/C++.
Связь с интерпретатором Python из кода на C осуществляется путем вызова функций, определенных в интерпретаторе Python. Все функции начинаются на Py или _Py, потому во избежание конфликтов в модулях расширения не следует определять функций с подобными именами.
Через C API доступны все встроенные возможности языка Python (при необходимости, детальнее изучить этот вопрос можно по документации):
высокоуровневый интерфейс интерпретатора (функции и макросы Py_Main(), PyRun_String(), PyRun_File(), Py_CompileString(), PyCompilerFlags() и т.п.),функции для работы со встроенным интерпретатором и потоками (Py_Initialize(), Py_Finalize(), Py_NewInterpreter(), Py_EndInterpreter(), Py_SetProgramName() и другие),управление подсчетом ссылок (макросы Py_INCREF(), Py_DECREF(), Py_XINCREF(), Py_XDECREF(), Py_CLEAR()).
Требуется при создании или удалении Python-объектов в C/C++-коде.обработка исключений (PyErr*-функции и PyExc_*-константы, например, PyErr_NoMemory() и PyExc_IOError)управление процессом и сервисы операционной системы (Py_FatalError(), Py_Exit(), Py_AtExit(), PyOS_CheckStack(), и другие функции/макросы PyOS*),импорт модулей (PyImport_Import() и другие),поддержка сериализации объектов (PyMarshal_WriteObjectToFile(), PyMarshal_ReadObjectFromFile() и т.п.)поддержка анализа строки аргументов (PyArg_ParseTuple(), PyArg_VaParse(), PyArg_ParseTupleAndKeywords(), PyArg_VaParseTupleAndKeywords(), PyArg_UnpackTuple() и Py_BuildValue()). С помощью этих функций облегчается задача получения в коде на C параметров, заданных при вызове функции из Python. Функции PyArg_Parse* принимают в качестве аргумента строку формата полученных аргументов,поддержка протоколов абстрактных объектов: + Протокол объекта (PyObject_Print(), PyObject_HasAttrString(), PyObject_GetAttrString(), PyObject_HasAttr(), PyObject_GetAttr(), PyObject_RichCompare(), ..., PyObject_IsInstance(), PyCallable_Check(), PyObject_Call(), PyObject_Dir() и другие). То, что должен уметь делать любой объект Python + Протокол числа (PyNumber_Check(), PyNumber_Add(), ..., PyNumber_And(), ..., PyNumber_InPlaceAdd(), ..., PyNumber_Coerce(), PyNumber_Int(), ...). То, что должен делать любой объект, представляющий число + Протокол последовательности (PySequence_Check(), PySequence_Size(), PySequence_Concat(), PySequence_Repeat(), PySequence_InPlaceConcat(), ..., PySequence_GetItem(), ..., PySequence_GetSlice(), PySequence_Tuple(), PySequence_Count(), ...) + Протокол отображения (например, словарь является отображением) (функции: PyMapping_Check(), PyMapping_Length(), PyMapping_HasKey(), PyMapping_Keys(), ..., PyMapping_SetItemString(), PyMapping_GetItemString() и др.) + Протокол итератора (PyIter_Check(), PyIter_Next()) + Протокол буфера (PyObject_AsCharBuffer(), PyObject_AsReadBuffer(), PyObject_AsWriteBuffer(), PyObject_CheckReadBuffer())поддержка встроенных типов данных.
Аналогично описанному в предыдущем пункте, но уже для конкретных встроенных типов данных. Например: + Булевский объект (PyBool_Check() - проверка принадлежности типу PyBool_Type, Py_False - объект False, Py_True - объект True,управление памятью (то есть кучей интерпретатора Python) (функции PyMem_Malloc(), PyMem_Realloc(), PyMem_Free(), PyMem_New(), PyMem_Resize(), PyMem_Del()). Разумеется, можно применять и средства выделения памяти C/C++, однако, в этом случае не будут использоваться преимущества управления памятью интерпретатора Python (сборка мусора и т.п.). Кроме того, освобождение памяти нужно производить тем же способом, что и ее выделение. Еще раз стоит напомнить, что повторное освобождение одной и той же области памяти (а равно использование области памяти после ее освобождения) чревато серьезными ошибками, которые компилятор C не имеет возможности распознать.структуры для определения объектов встроенных типов (PyObject, PyVarObject и много других)
Примечание
Под протоколом здесь понимается набор методов, которые должен поддерживать тот или иной класс для организации операций со своими экземплярами. Эти методы доступны не только из Python (например, len(a) дает длину последовательности), но и из кода на C (PySequence_Length()).
Интеграция Python и других систем программирования
Язык программирования Python является сценарным языком, а значит его основное назначение - интеграция в единую систему разнородных программных компонентов. Выше рассматривалась (низкоуровневая) интеграция с C/C++-приложениями. Нужно заметить, что в большинстве случаев достаточно интеграции с использованием протокола. Например, интегрируемые приложения могут общаться через XML-RPC, SOAP, CORBA, COM, .NET и т.п. В случаях, когда приложения имеют интерфейс командной строки, их можно вызывать из Python и управлять стандартным вводом-выводом, переменными окружения. Однако есть и более интересные варианты интеграции.
Современное состояние дел по излагаемому вопросу можно узнать по адресу: http://www.python.org/moin/IntegratingPythonWithOtherLanguages
Использование SWIG
SWIG (Simplified Wrapper and Interface Generator, упрощенный упаковщик и генератор интерфейсов) - это программное средства, сильно упрощающее (во многих случаях - автоматизирующее) использование библиотек, написанных на C и C++, а также на других языках программирования, в том числе (не в последнюю очередь!) на Python. Нужно отметить, что SWIG обеспечивает достаточно полную поддержку практически всех возможностей C++, включая предобработку, классы, указатели, наследование и даже шаблоны C++. Последнее очень важно, если необходимо создать интерфейс к библиотеке шаблонов.
Пользоваться SWIG достаточно просто, если уметь применять компилятор и компоновщик (что в любом случае требуется при программировании на C/C++).
Java
Документация по Jython (это реализация Python на Java-платформе) отмечает, что Jython обладает следующими неоспоримыми преимуществами над другими языками, использующими Java-байт-код:
Jython-код динамически компилирует байт-коды Java, хотя возможна и статическая компиляция, что позволяет писать апплеты, сервлеты и т.п.;Поддерживает объектно-ориентированную модель Java, в том числе, возможность наследовать от абстрактных Java-классов;Jython является реализацией Python - языка с практичным синтаксисом, обладающего большой выразительностью, что позволяет сократить сроки разработки приложений в разы.
Правда, имеются и некоторые ограничения по сравнению с "обычным" Python. Например, Java не поддерживает множественного наследования, поэтому в некоторых версиях Jython нельзя наследовать классы от нескольких Java-классов (в тоже время, множественное наследование поддерживается для Python-классов).
Следующий пример (файл lines.py) показывает полную интеграцию Java-классов с интерпретатором Python:
# Импортируются модули из Java from java.lang import System from java.awt import * # А это модуль из Jython import random
# Класс для рисования линий на рисунке class Lines(Canvas): # Реализация метода paint() def paint(self, g): X, Y = self.getSize().width, self.getSize().height label.setText("%s x %s" % (X, Y)) for i in range(100): x1, y1 = random.randint(1, X), random.randint(1, Y) x2, y2 = random.randint(1, X), random.randint(1, Y) g.drawLine(x1, y1, x2, y2)
# Метки, кнопки и т.п. panel = Panel(layout=BorderLayout()) label = Label("Size", Label.RIGHT) panel.add(label, "North") button = Button("QUIT", actionPerformed=lambda e: System.exit(0)) panel.add(button, "South") lines = Lines() panel.add(lines, 'Center')
# Запуск панели в окне import pawt pawt.test(panel, size=(240, 240))
Программы на Jython можно компилировать в Java и собирать в jar-архивы. Для создания jar-архива на основе модуля (или пакета) можно применить команду jythonc, которая входит в комплект Jython. Из командной строки это можно сделать примерно так:
jythonс -d -c -j lns.jar lines.py
Для запуска приложения достаточно запустить lines из командной строки:
java -classpath "$CLASSPATH" lines
В переменной $CLASSPATH должны быть пути к архивам lns.jar и jython.jar.
Написание модуля расширения
Если необходимость встроить Python в программу возникает нечасто, то его расширение путем написания модулей на C/C++ - довольно распространенная практика. Изначально Python был нацелен на возможность расширения, поэтому в настоящий момент очень многие C/C++-библиотеки имеют привязки к Python.
Привязка к Python, хотя и может быть несколько автоматизирована, все же это процесс творческий. Дело в том, что если предполагается интенсивно использовать библиотеку в Python, ее привязку желательно сделать как можно более тщательно. Возможно, в ходе привязки будет сделана объектно-ориентированная надстройка или другие архитектурные изменения, которые позволят упростить использование библиотеки.
В качестве примера можно привести выдержку из исходного кода модуля md5, который реализует функцию для получения md5-дайджеста. Модуль приводится в целях иллюстрации (то есть, с сокращениями). Модуль вводит собственный тип данных, MD5Type, поэтому можно увидеть не только реализацию функций, но и способ описания встроенного типа. В рамках этого курса не изучить все тонкости программирования модулей расширения, главное понять дух этого занятия. На комментарии автора курса лекций указывает двойной слэш //:
// заголовочные файлы #include "Python.h" #include "md5.h"
// В частности, в заголовочном файле md5.h есть следующие определения: // typedef unsigned char *POINTER; // typedef unsigned int UINT4;
// typedef struct { // UINT4 state[4]; /* state (ABCD) */ // UINT4 count[2]; /* number of bits, modulo 2^64 (lsb first) */ // unsigned char buffer[64]; /* input buffer */ // } MD5_CTX;
// Структура объекта MD5type typedef struct { PyObject_HEAD MD5_CTX md5; /* the context holder */ } md5object;
// Определение типа объекта MD5type static PyTypeObject MD5type;
// Макрос проверки типа MD5type #define is_md5object(v) ((v)->ob_type == &MD5type)
// Порождение объекта типа MD5type static md5object * newmd5object(void) { md5object *md5p; md5p = PyObject_New(md5object, &MD5type); if (md5p == NULL) return NULL; // не хватило памяти MD5Init(&md5p->md5); // инициализация return md5p; }
// Определения методов
// Освобождение памяти из-под объекта static void md5_dealloc(md5object *md5p) { PyObject_Del(md5p); }
static PyObject * md5_update(md5object *self, PyObject *args) { unsigned char *cp; int len;
// разбор строки аргументов. Формат указывает следующее: // s# - один параметр, строка (заданная указателем и длиной) // : - разделитель // update - название метода if (!PyArg_ParseTuple(args, "s#:update", &cp, &len)) return NULL;
MD5Update(&self->md5, cp, len);
// Даже возврат None требует увеличения счетчика ссылок Py_INCREF(Py_None); return Py_None; }
// Строка документации метода update PyDoc_STRVAR(update_doc, "update (arg)\n\ \n\ Update the md5 object with the string arg. Repeated calls are\n\ equivalent to a single call with the concatenation of all the\n\ arguments.");
// Метод digest static PyObject * md5_digest(md5object *self) { MD5_CTX mdContext; unsigned char aDigest[16];
/* make a temporary copy, and perform the final */ mdContext = self->md5; MD5Final(aDigest, &mdContext);
// результат возвращается в виде строки return PyString_FromStringAndSize((char *)aDigest, 16); }
// и строка документации PyDoc_STRVAR(digest_doc, "digest() -> string\n\ ...");
static PyObject * md5_hexdigest(md5object *self) { // Реализация метода на C }
PyDoc_STRVAR(hexdigest_doc, "hexdigest() -> string\n...");
// Здесь было определение метода copy()
// Методы объекта в сборе. // Для каждого метода указывается название, имя метода на C // (с приведением к типу PyCFunction), способ передачи аргументов: // METH_VARARGS (переменное кол-во) или METH_NOARGS (нет аргументов) // В конце массива - метка окончания спиcка аргументов. static PyMethodDef md5_methods[] = { {"update", (PyCFunction)md5_update, METH_VARARGS, update_doc}, {"digest", (PyCFunction)md5_digest, METH_NOARGS, digest_doc}, {"hexdigest", (PyCFunction)md5_hexdigest, METH_NOARGS, hexdigest_doc}, {"copy", (PyCFunction)md5_copy, METH_NOARGS, copy_doc}, {NULL, NULL} /* sentinel */ };
// Атрибуты md5- объекта обслуживает эта функция, реализуя метод // getattr. static PyObject * md5_getattr(md5object *self, char *name) { // атрибут-данное digest_size if (strcmp(name, "digest_size") == 0) { return PyInt_FromLong(16); } // поиск атрибута-метода ведется в списке return Py_FindMethod(md5_methods, (PyObject *)self, name); }
// Строка документации к модулю md5 PyDoc_STRVAR(module_doc, "This module implements ...");
// Строка документации к классу md5 PyDoc_STRVAR(md5type_doc, "An md5 represents the object...");
// Структура для объекта MD5type с описаниями для интерпретатора static PyTypeObject MD5type = { PyObject_HEAD_INIT(NULL) 0, /*ob_size*/ "md5.md5", /*tp_name*/ sizeof(md5object), /*tp_size*/ 0, /*tp_itemsize*/ /* methods */ (destructor)md5_dealloc, /*tp_dealloc*/ 0, /*tp_print*/ (getattrfunc)md5_getattr, /*tp_getattr*/ 0, /*tp_setattr*/ 0, /*tp_compare*/ 0, /*tp_repr*/ 0, /*tp_as_number*/ 0, /*tp_as_sequence*/ 0, /*tp_as_mapping*/ 0, /*tp_hash*/ 0, /*tp_call*/ 0, /*tp_str*/ 0, /*tp_getattro*/ 0, /*tp_setattro*/ 0, /*tp_as_buffer*/ 0, /*tp_xxx4*/ md5type_doc, /*tp_doc*/ };
// Функции модуля md5:
// Функция new() для получения нового объекта типа md5type static PyObject * MD5_new(PyObject *self, PyObject *args) { md5object *md5p; unsigned char *cp = NULL; int len = 0;
// Разбор параметров. Здесь вертикальная черта // в строке формата означает окончание // списка обязательных параметров. // Остальное - как и выше: s# - строка, после : - имя if (!PyArg_ParseTuple(args, "|s#:new", &cp, &len)) return NULL;
if ((md5p = newmd5object()) == NULL) return NULL;
// Если был задан параметр cp: if (cp) MD5Update(&md5p->md5, cp, len);
return (PyObject *)md5p; }
// Строка документации для new() PyDoc_STRVAR(new_doc, "new([arg]) -> md5 object ...");
// Список функций, которые данный модуль экспортирует static PyMethodDef md5_functions[] = { {"new", (PyCFunction)MD5_new, METH_VARARGS, new_doc}, {"md5", (PyCFunction)MD5_new, METH_VARARGS, new_doc}, {NULL, NULL} /* Sentinel */ }; // Следует заметить, что md5 - то же самое, что new.
Эта функция оставлена для // обратной совместимости со старым модулем md5
// Инициализация модуля PyMODINIT_FUNC initmd5(void) { PyObject *m, *d;
MD5type.ob_type = &PyType_Type; // Инициализируется модуль m = Py_InitModule3("md5", md5_functions, module_doc); // Получается словарь с именами модуля d = PyModule_GetDict(m); // Добавляется атрибут MD5Type (тип md5-объекта) к словарю PyDict_SetItemString(d, "MD5Type", (PyObject *)&MD5type); // Добавляется целая константа digest_size к модулю PyModule_AddIntConstant(m, "digest_size", 16); }
На основе этого примера можно строить собственные модули расширения, ознакомившись с документацией по C/API и документом "Extending and Embedding" ("Расширение и встраивание") из стандартной поставки Python. Перед тем, как приступать к созданию своего модуля, следует убедиться, что это целесообразно: подходящего модуля еще не создано и реализация в виде чистого Python неэффективна. Если создан действительно полезный модуль, его можно предложить для включения в поставку Python. Для этого нужно просто связаться с кем-нибудь из разработчиков по электронной почте или предложить модуль в виде "патча" через http://sourceforge.net.
OCaml
Язык программирования OCaml - это язык функционального программирования (семейства ML, что означает Meta Language), созданный в институте INRIA, Франция. Важной особенностью OCaml является то, что его компилятор порождает исполняемый код, по быстродействию сравнимый с С, родной для платформ, на которых OCaml реализован. В то же время, будучи функциональным по своей природе, он приближается к Python по степени выразительности. Именно поэтому для OCaml была создана библиотека Pycaml, фактически реализующая аналог C API для OCaml. Таким образом, в программах на OCaml могут использоваться модули языка Python, в них даже может быть встроен интерпретатор Python. Для Python имеется большое множество адаптированных C-библиотек, это дает возможность пользователям OCaml применять в разработке комбинированное преимущество Python и OCaml. Минусом является только необходимость знать функции Python/C API, имена которого использованы для связи OCaml и Python.
Следующий пример (из Pycaml) показывает программу для OCaml, которая определяет модуль для Python на OCaml и вызывает встроенный интерпретатор Python:
let foo_bar_print = pywrap_closure (fun x -> pytuple_fromarray (pytuple_toarray x)) ;; let sd = pyimport_getmoduledict () ;; let mx = pymodule_new "CamlModule" ;; let cd = pydict_new () ;; let cx = pyclass_new (pynull (), cd, pystring_fromstring "CamlClass") ;; let cmx = pymethod_new (foo_bar_print,(pynull ()),cx) ;; let _ = pydict_setitemstring (cd, "CamlMethod", cmx) ;; let _ = pydict_setitemstring (pymodule_getdict mx, "CamlClass", cx) ;; let _ = pydict_setitemstring (sd, "CamlModule", mx) ;; let _ = pyrun_simplestring ("from CamlModule import CamlClass\n" ^ "x = CamlClass()\n" ^ "for i in range(100000):\n" ^ " x.CamlMethod(1,2,3,4)\n" ^ "print 'Done'\n")
Пример встраивания интерпретатора в программу на C
Интерпретатор Python может быть встроен в программу на C с использованием C API. Это лучше всего демонстрирует уже работающий пример:
/* File : demo.c */ /* Пример встраивания интерпретатора Python в другую программу */ #include "Python.h"
main(int argc, char **argv) { /* Передает argv[0] интерпретатору Python */ Py_SetProgramName(argv[0]);
/* Инициализация интерпретатора */ Py_Initialize();
/* ... */
/* Выполнение операторов Python (как бы модуль __main__) */ PyRun_SimpleString("import time\n"); PyRun_SimpleString("print time.localtime(time.time())\n");
/* ... */
/* Завершение работы интерпретатора */ Py_Finalize(); }
Компиляция этого примера с помощью компилятора gcc может быть выполнена, например, так:
ver="2.3" gcc -fpic demo.c -DHAVE_CONFIG_H -lm -lpython${ver} \ -lpthread -lutil -ldl \ -I/usr/local/include/python${ver} \ -L/usr/local/lib/python${ver}/config \ -Wl,-E \ -o demo
Здесь следует отметить следующие моменты:
программу необходимо компилировать вместе с библиотекой libpython соответствующей версии (для этого используется опция -l, за которой следует имя библиотеки) и еще с библиотеками, которые требуются для Python: libpthread, libm, libutil и т.п.)опция pic порождает код, не зависящий от позиции, что позволяет в дальнейшем динамически компоновать кодобычно требуется явно указать каталог, в котором лежит заголовочный файл Python.h (в gcc это делается опцией -I)чтобы получившийся исполняемый файл мог корректно предоставлять имена для динамически загружаемых модулей, требуется передать компоновщику опцию -E: это можно сделать из gcc с помощью опции -Wl,-E. (В противном случае, модуль time, а это модуль расширения в виде динамически загружаемого модуля, не будет работать из-за того, что не увидит имен, определенных в libpython)
Здесь же следует сделать еще одно замечание: программа, встраивающая Python, не должна много раз выполнять Py_Initialize() и Py_Finalize(), так как это может приводить к утечке памяти. Сам же интерпретатор Python очень стабилен и в большинстве случаев не дает утечек памяти.
Prolog
Для тех, кто хочет использовать Prolog из Python, существует несколько возможностей:
Версия GNU Prolog (сайт: http://gprolog.sourceforge.net) интегрируется с Python посредством пакета bedevere (сайт: http://bedevere.sourceforge.net)Имеется пакет PyLog (http://www.gocept.com/angebot/opensource/Pylog) для работы с SWI-Prolog (http://www.swi-prolog.org) из PythonМожно использовать пакет pylog (доступен с сайта: http://christophe.delord.free.fr/en/pylog/), который добавляет основные возможности Prolog в Python
Эти три варианта реализуют различные способы интеграции возможностей Prolog в Python. Первый вариант использует SWIG, второй организует общение с Prolog-системой через конвейер, а третий является специализированной реализацией Prolog.
Следующий пример показывает использование модуля pylog:
from pylog import *
exec(compile(r""" man('Socrates'). man('Democritus'). mortal(X) :- man(X). """))
WHO = Var() queries = [mortal('Socrates'), man(WHO), mortal(WHO)] for query in queries: print "?", query for _ in query(): print " yes:", query
Что выдает результат:
? mortal(Socrates) yes: mortal(Socrates) ? man(_) yes: man(Socrates) yes: man(Democritus) ? mortal(_) yes: mortal(Socrates) yes: mortal(Democritus)
Разумеется, это не "настоящий" Prolog, но с помощью модуля pylog любой, кому требуются логические возможности Prolog в Python, может написать программу с использованием Prolog-синтаксиса.
Простой пример использования SWIG
Предположим, что есть программа на C, реализующая некоторую функцию (пусть это будет вычисление частоты появления различных символов в строке):
/* File : freq.c */ #include <stdlib.h>
int * frequency(char s[]) { int *freq; char *ptr; freq = (int*)(calloc(256, sizeof(int))); if (freq != NULL) for (ptr = s; *ptr; ptr++) freq[*ptr] += 1; return freq; }
Для того чтобы можно было воспользоваться этой функцией из Python, нужно написать интерфейсный файл (расширение .i) примерно следующего содержания:
/* File : freq.i */ %module freq
%typemap(out) int * { int i; $result = PyTuple_New(256); for(i=0; i<256; i++) PyTuple_SetItem($result, i, PyLong_FromLong($1[i])); free($1); }
extern int * frequency(char s[]);
Интерфейсные файлы содержат инструкции самого SWIG и фрагменты C/C++-кода, возможно, с макровключениями (в примере выше: $result, $1). Следует заметить, что для преобразования массива целых чисел в кортеж элементов типа long, необходимо освободить память из-под исходного массива, в котором подсчитывались частоты.
Теперь (подразумевая, что используется компилятор gcc), создание модуля расширения может быть выполнено примерно так:
swig -python freq.i gcc -c -fpic freq_wrap.c freq.c -DHAVE_CONFIG_H -I/usr/local/include/python2.3 -I/usr/local/lib/python2.3/config gcc -shared freq.o freq_wrap.o -o _freq.so
После этого в рабочем каталоге появляется файлы _freq.so и freq.py, которые вместе и дают доступ к требуемой функции:
>>> import freq >>> freq.frequency("ABCDEF")[60:75] (0L, 0L, 0L, 0L, 0L, 1L, 1L, 1L, 1L, 1L, 1L, 0L, 0L, 0L, 0L)
Помимо этого, можно посмотреть на содержимое файла freq_wrap.c, который был порожден SWIG: в нем, среди прочих вспомогательных определений, нужных самому SWIG, можно увидеть что-то подобное проиллюстрированному выше примеру модуля md5. Вот фрагмент этого файла с определением обертки для функции frequency():
extern int *frequency(char []); static PyObject *_wrap_frequency(PyObject *self, PyObject *args) { PyObject *resultobj; char *arg1 ; int *result;
if(!PyArg_ParseTuple(args,(char *)"s:frequency",&arg1)) goto fail; result = (int *)frequency(arg1);
{ int i; resultobj = PyTuple_New(256); for(i=0; i<256; i++) PyTuple_SetItem(resultobj, i, PyLong_FromLong(result[i])); free(result); } return resultobj; fail: return NULL; }
В качестве упражнения, предлагается сопоставить это определение с файлом freq.i и понять, что происходит внутри функции _wrap_frequency(). Подсказка: можно посмотреть еще раз комментарии к C-коду модуля md5.
Стоит еще раз напомнить, что в отличие от Python, в языке C/C++ управление памятью должно происходить в явном виде. Именно поэтому добавлена функция free() при преобразовании типа. Если этого не сделать, возникнут утечки памяти. Эти утечки можно обнаружить, при многократном выполнении функции:
>>> import freq >>> for i in xrange(1000000): ... dummy = freq.frequency("ABCDEF") >>>
Если функция freq.frequency() имеет утечки памяти, выполняемый процесс очень быстро займет всю имеющуюся память.
Pyrex
Для написания модулей расширения можно использовать специальный язык - Pyrex - который совмещает синтаксис Python и типы данных C. Компилятор Pyrex написан на Python и превращает исходный файл (например, primes.pyx) в файл на C - готовый для компиляции модуль расширения. Язык Pyrex заботится об управлении памятью, удаляя после себя ставшие ненужными объекты. Пример файла из документации к Pyrex (для вычисления простых чисел):
def primes(int kmax): cdef int n, k, i cdef int p[1000] result = [] if kmax > 1000: kmax = 1000 k = 0 n = 2 while k < kmax: i = 0 while i < k and n % p[i] <> 0: i = i + 1 if i == k: p[k] = n k = k + 1 result.append(n) n = n + 1 return result
В результате применения компилятора Pyrex, нехитрой компиляции и компоновки (с помощью GCC):
pyrexc primes.pyx gcc primes.c -c -fPIC -I /usr/local/include/python2.3 gcc -shared primes.o -o primes.so
Получается модуль расширения с функцией primes():
>>> import primes >>> primes.primes(25) [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
Разумеется, в Pyrex можно использовать C-библиотеки, именно поэтому он, как и SWIG, может служить для построения оберток C-библиотек для Python.
Следует отметить, что для простых операций Pyrex применяет C, а для обращения к объектам Python - вызовы Python/C API. Таким образом, объединяется выразительность Python и эффективность C. Конечно, некоторые вещи в Pyrex не доступны, например, генераторы, списковые включения и Unicode, однако, цель Pyrex - создание быстродействующих модулей расширения, и для этого он превосходно подходит. Ознакомится с Pyrex можно по документации (которая, к сожалению, есть пока только на английском языке).
В этой лекции кратко рассматривались
В этой лекции кратко рассматривались основные возможности интеграции интерпретатора Python и других систем программирования. Базовая реализация языка Python написана на C, поэтому Python имеет программный интерфейс Python/C API, который позволяет программам на C/C++ обращаться к интерпретатору Python, отдельным объектам, модулям и типам данных. Состав Python/C API достаточно обширен, поэтому речь шла лишь о некоторых основных его элементах.
Был рассмотрен процесс написания модуля расширения на C как напрямую, так и с использованием генератора интерфейсов SWIG. Также кратко говорилось о возможности встраивания интерпретатора Python в программу на С или OCaml.
Язык Python (с помощью специальной его реализации - Jython) прозрачно интегрируется с языком Java: в Python-программе, выполняемой под Jython в Java-апплете или Java-приложении, можно использовать практически любые Java-классы.
На примере языка Prolog были показаны различные подходы к добавлению возможностей логического вывода в Python-программы: независимая реализация Prolog-машины, связь с Prolog-интерпретатором через конвейер, связь через Python/C API.
Интересный гибрид C и Python представляет из себя язык Pyrex. Этот язык создан с целью упростить написание модулей расширения для Python на C, и использует структуры данных C и подобный Python синтаксис. Несмотря на некоторые смысловые и синтаксические отличия как от C, так и от Python, язык Pyrex помогает существенно сократить время разработки модулей расширения, сохранив эффективность компилятора C и знакомый синтаксис Python.
В данной лекции не были представлены другие возможности интеграции, например библиотека шаблонов C++ Boost Python, которая позволяет интегрировать Python и C++. Кроме того, из Python можно использовать библиотеки, написанные на Фортране (проект F2PY).
Развитые и гибкие интеграционные возможности Python являются его основным преимуществом в качестве языка для интеграции приложений. Из лекции нетрудно заключить, что Python легко взаимодействует с другими системами.
Исследование объекта
Даже самые примитивные объекты в языке программирования Python имеют возможности, общие для всех объектов: можно получить их уникальный идентификатор (с помощью функции id()), представление в виде строки - даже в двух вариантах (функции str() и repr()); можно узнать атрибуты объекта с помощью встроенной функции dir() и во многих случаях пользоваться атрибутом __dict__ для доступа к словарю имен объекта. Также можно узнать, сколько других объектов ссылается на данный с помощью функции sys.getrefcount(). Есть еще сборка мусора, которая применяется для освобождения памяти от объектов, которые более не используются, но имеют ссылки друг на друга (циклические ссылки). Сборкой мусора (garbage collection) можно управлять из модуля gc.
Все это подчеркивает тот факт, что объекты в Python существуют не сами по себе, а являются частью системы: они и их отношения строго учитываются интерпретатором.
Сразу же следует оговориться, что Python имеет две стороны интроспекции: "официальную", которую поддерживает описание языка и многие его реализации, и "неофициальную", которая использует особенности той или иной реализации. С помощью "официальных" средств интроспекции можно получить информацию о принадлежности объекта тому или иному классу (функция type()), проверить принадлежность экземпляра классу (isinstance()), отношение наследования между классами (issubclass()), а также получить информацию, о которой говорилось чуть выше. Это как бы приборная доска машины. С помощью "неофициальной" интроспекции (это то, что под капотом) можно получить доступ к чему угодно: к текущему фрейму исполнения и стеку, к байт-коду функции, к некоторым механизмам интерпретатора (от загрузки модулей до полного контроля над внутренней средой исполнения). Сразу же стоит сказать, что этот механизм следует рассматривать (и тем более вносить изменения) очень деликатно: разработчики языка не гарантируют постоянство этих механизмов от версии к версии, а некоторые полезные модули используют эти механизмы для своих целей.
Например, упомянутый ранее ускоритель выполнения Python- кода psyco очень серьезно вмешивается во фреймы исполнения, заменяя их своими объектами. Кроме того, разные реализации Python могут иметь совсем другие внутренние механизмы.
Сказанное стоит подкрепить примерами.
В первом примере исследуется объект с помощью "официальных" средств. В качестве объекта выбрана обычная строка:
>>> s = "abcd" >>> dir(s) ['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__str__', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'replace', 'rfind', 'rindex', 'rjust', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill'] >>> id(s) 1075718400 >>> print str(s) abcd >>> print repr(s) 'abcd' >>> type(s) <type 'str'> >>> isinstance(s, basestring) True >>> isinstance(s, int) False >>> issubclass(str, basestring) True
"Неофициальные" средства интроспекции в основном работают в области представления объектов в среде интерпретатора. Ниже будет рассмотрено, как главная (на настоящий момент) реализация Python может дать информацию об определенной пользователем функции:
>>> def f(x, y=0): ... """Function f(x, y)""" ... global s ... return t + x + y ... >>> f.secure = 1 # присваивается дополнительный атрибут >>> f.func_name # имя 'f' >>> f.func_doc # строка документации 'Function f(x, y)' >>> f.func_defaults # значения по умолчанию (0,) >>> f.func_dict # словарь атрибутов функции {'secure': 1} >>> co = f.func_code # кодовый объект >>> co <code object f at 0x401ec7e0, file "<stdin>", line 1>
Кодовые объекты имеют свои атрибуты:
>>> co.co_code # байт-код 't\x00\x00|\x00\x00\x17|\x01\x00\x17Sd\x01\x00S' >>> co.co_argcount # число аргументов 2 >>> co.co_varnames # имена переменных ('x', 'y') >>> co.co_consts # константы (None,) >>> co.co_names # локальные имена ('t', 'x', 'y') >>> co.co_name # имя блока кода (в нашем случае - имя функции) 'f'
и так далее. Более правильно использовать для получения всех этих сведений модуль inspect.
Изучение байт-кода
Для изучения байт-кода Python-программы можно использовать модуль dis (сокращение от "дизассемблер"), который содержит функции, позволяющие увидеть байт-код в мнемоническом виде. Следующий пример иллюстрирует эту возможность:
>>> def f(): ... print 2*2 ... >>> dis.dis(f) 2 0 LOAD_CONST 1 (2) 3 LOAD_CONST 1 (2) 6 BINARY_MULTIPLY 7 PRINT_ITEM 8 PRINT_NEWLINE 9 LOAD_CONST 0 (None) 12 RETURN_VALUE
Определяется функция f(), которая должна вычислить и напечатать значение выражения 2*2. Функция dis() модуля dis выводит код функции f() в виде некого "ассемблера", в котором байт-код Python представлен мнемоническими именами. Следует заметить, что при интерпретации используется стек, поэтому LOAD_CONST кладет значение на вершину стека, а BINARY_MULTIPLY берет со стека два значения и помещает на стек результат их перемножения. Функция без оператора return возвращает значение None. Как и в случае с кодами для микропроцессора, некоторые байт-коды принимают параметры.
Мнемонические имена можно увидеть в списке dis.opname (ниже печатаются только задействованные имена):
>>> import dis >>> [n for n in dis.opname if n[0] != "<"] ['STOP_CODE', 'POP_TOP', 'ROT_TWO', 'ROT_THREE', 'DUP_TOP', 'ROT_FOUR', 'NOP', 'UNARY_POSITIVE', 'UNARY_NEGATIVE', 'UNARY_NOT', 'UNARY_CONVERT', 'UNARY_INVERT', 'LIST_APPEND', 'BINARY_POWER', 'BINARY_MULTIPLY', 'BINARY_DIVIDE', 'BINARY_MODULO', 'BINARY_ADD', 'BINARY_SUBTRACT', 'BINARY_SUBSCR', 'BINARY_FLOOR_DIVIDE', 'BINARY_TRUE_DIVIDE', 'INPLACE_FLOOR_DIVIDE', 'INPLACE_TRUE_DIVIDE', 'SLICE+0', 'SLICE+1', 'SLICE+2', 'SLICE+3', 'STORE_SLICE+0', 'STORE_SLICE+1', 'STORE_SLICE+2', 'STORE_SLICE+3', 'DELETE_SLICE+0', 'DELETE_SLICE+1', 'DELETE_SLICE+2', 'DELETE_SLICE+3', 'INPLACE_ADD', 'INPLACE_SUBTRACT', 'INPLACE_MULTIPLY', 'INPLACE_DIVIDE', 'INPLACE_MODULO', 'STORE_SUBSCR', 'DELETE_SUBSCR', 'BINARY_LSHIFT', 'BINARY_RSHIFT', 'BINARY_AND', 'BINARY_XOR', 'BINARY_OR', 'INPLACE_POWER', 'GET_ITER', 'PRINT_EXPR', 'PRINT_ITEM', 'PRINT_NEWLINE', 'PRINT_ITEM_TO', 'PRINT_NEWLINE_TO', 'INPLACE_LSHIFT', 'INPLACE_RSHIFT', 'INPLACE_AND', 'INPLACE_XOR', 'INPLACE_OR', 'BREAK_LOOP', 'LOAD_LOCALS', 'RETURN_VALUE', 'IMPORT_STAR', 'EXEC_STMT', 'YIELD_VALUE', 'POP_BLOCK', 'END_FINALLY', 'BUILD_CLASS', 'STORE_NAME', 'DELETE_NAME', 'UNPACK_SEQUENCE', 'FOR_ITER', 'STORE_ATTR', 'DELETE_ATTR', 'STORE_GLOBAL', 'DELETE_GLOBAL', 'DUP_TOPX', 'LOAD_CONST', 'LOAD_NAME', 'BUILD_TUPLE', 'BUILD_LIST', 'BUILD_MAP', 'LOAD_ATTR', 'COMPARE_OP', 'IMPORT_NAME', 'IMPORT_FROM', 'JUMP_FORWARD', 'JUMP_IF_FALSE', 'JUMP_IF_TRUE', 'JUMP_ABSOLUTE', 'LOAD_GLOBAL', 'CONTINUE_LOOP', 'SETUP_LOOP', 'SETUP_EXCEPT', 'SETUP_FINALLY', 'LOAD_FAST', 'STORE_FAST', 'DELETE_FAST', 'RAISE_VARARGS', 'CALL_FUNCTION', 'MAKE_FUNCTION', 'BUILD_SLICE', 'MAKE_CLOSURE', 'LOAD_CLOSURE', 'LOAD_DEREF', 'STORE_DEREF', 'CALL_FUNCTION_VAR', 'CALL_FUNCTION_KW', 'CALL_FUNCTION_VAR_KW', 'EXTENDED_ARG']
Легко догадаться, что LOAD означает загрузку значения в стек, STORE - выгрузку, PRINT - печать, BINARY - бинарную операцию и т.п.
Лексический анализ
Лексический анализатор языка программирования разбивает исходный текст программы (состоящий из одиночных символов) на лексемы - неделимые "слова" языка.
Основные категории лексем Python: идентификаторы и ключевые слова (NAME), литералы (STRING, NUMBER и т.п.), операции (OP), разделители, специальные лексемы для обозначения (изменения) отступов (INDENT, DEDENT) и концов строк (NEWLINE), а также комментарии (COMMENT). Лексический анализатор доступен через модуль tokenize, а определения кодов лексем содержатся в модуле token стандартной библиотеки Python. Следующий пример показывает лексический анализатор в действии:
import StringIO, token, tokenize
prog_example = """ for i in range(100): # comment if i % 1 == 0: \ print ":", t**2 """.strip()
rl = StringIO.StringIO(prog_example).readline
for t_type, t_str, (br,bc), (er,ec), logl in tokenize.generate_tokens(rl): print "%3i %10s : %20r" % (t_type, token.tok_name[t_type], t_str)
А вот что выведет эта программа, разбив на лексемы исходный код примера:
prog_example:
1 NAME : 'for' 1 NAME : 'i' 1 NAME : 'in' 1 NAME : 'range' 50 OP : '(' 2 NUMBER : '100' 50 OP : ')' 50 OP : ':' 52 COMMENT : '# comment' 4 NEWLINE : '\n' 5 INDENT : ' ' 1 NAME : 'if' 1 NAME : 'i' 50 OP : '%' 2 NUMBER : '1' 50 OP : '==' 2 NUMBER : '0' 50 OP : ':' 1 NAME : 'print' 3 STRING : '":"' 50 OP : ',' 1 NAME : 't' 50 OP : '**' 2 NUMBER : '2' 6 DEDENT : '' 0 ENDMARKER : ''
Фактически получен поток лексем, который может использоваться для различных целей. Например, для синтаксического "окрашивания" кода на языке Python. Словарь token.tok_name позволяет получить мнемонические имена для типа лексемы по номеру.
Модуль inspect
Основное назначение модуля inspect - давать приложению информацию о модулях, классах, функциях, трассировочных объектах, фреймах исполнения и кодовых объектах. Именно модуль inspect позволяет заглянуть "на кухню" интерпретатора Python.
Модуль имеет функции для проверки принадлежности объектов различным типам, с которыми он работает:
| inspect.isbuiltin | Встроенная функция |
| inspect.isclass | Класс |
| inspect.iscode | Код |
| inspect.isdatadescriptor | Описатель данных |
| inspect.isframe | Фрейм |
| inspect.isfunction | Функция |
| inspect.ismethod | Метод |
| inspect.ismethoddescriptor | Описатель метода |
| inspect.ismodule | Модуль |
| inspect.isroutine | Функция или метод |
| inspect.istraceback | Трассировочный объект |
Пример:
>>> import inspect >>> inspect.isbuiltin(len) True >>> inspect.isroutine(lambda x: x+1) True >>> inspect.ismethod(''.split) False >>> inspect.isroutine(''.split) True >>> inspect.isbuiltin(''.split) True
Объект типа модуль появляется в Python-программе благодаря операции импорта. Для получения информации о модуле имеются некоторые функции, а объект-модуль обладает определенными атрибутами, как продемонстрировано ниже:
>>> import inspect >>> inspect.ismodule(inspect) True >>> inspect.getmoduleinfo('/usr/local/lib/python2.3/inspect.pyc') ('inspect', '.pyc', 'rb', 2) >>> inspect.getmodulename('/usr/local/lib/python2.3/inspect.pyc') 'inspect' >>> inspect.__name__ 'inspect' >>> inspect.__dict__ . . . >>> inspect.__doc__ "Get useful information from live Python objects.\n\nThis module encapsulates .. . .
Интересны некоторые функции, которые предоставляют информацию об исходном коде объектов:
>>> import inspect >>> inspect.getsourcefile(inspect) # имя файла исходного кода '/usr/local/lib/python2.3/inspect.py' >>> inspect.getabsfile(inspect) # абсолютный путь к файлу '/usr/local/lib/python2.3/inspect.py' >>> print inspect.getfile(inspect) # файл кода модуля /usr/local/lib/python2.3/inspect.pyc >>> print inspect.getsource(inspect) # исходный текст модуля (в виде строки) # -*- coding: iso-8859-1 -*- """Get useful information from live Python objects. . . . >>> import smtplib >>> # Комментарий непосредственно перед определением объекта: >>> inspect.getcomments(smtplib.SMTPException) '# Exception classes used by this module.\n' >>> # Теперь берем строку документирования: >>> inspect.getdoc(smtplib.SMTPException) 'Base class for all exceptions raised by this module.'
С помощью модуля inspect можно узнать состав аргументов некоторой функции с помощью функции inspect.getargspec():
>>> import inspect >>> def f(x, y=1, z=2): ... return x + y + z ... >>> def g(x, *v, **z): ... return x ... >>> print inspect.getargspec(f) (['x', 'y', 'z'], None, None, (1, 2)) >>> print inspect.getargspec(g) (['x'], 'v', 'z', None)
Возвращаемый кортеж содержит список аргументов (кроме специальных), затем следуют имена аргументов для списка позиционных аргументов (*) и списка именованных аргументов (**), после чего - список значений по умолчанию для последних позиционных аргументов. Первый аргумент-список может содержать вложенные списки, отражая структуру аргументов:
>>> def f((x1,y1), (x2,y2)): ... return 1 ... >>> print inspect.getargspec(f) ([['x1', 'y1'], ['x2', 'y2']], None, None, None)
Классы (как вы помните) - тоже объекты, и о них можно кое-что узнать:
>>> import smtplib >>> s = smtplib.SMTP >>> s.__module__ # модуль, в котором был определен объект 'smtplib' >>> inspect.getmodule(s) # можно догадаться о происхождении объекта <module 'smtplib' from '/usr/local/lib/python2.3/smtplib.pyc'>
Для визуализации дерева классов может быть полезна функция inspect.getclasstree(). Она возвращает иерархически выстроенный в соответствии с наследованием список вложенных списков классов, указанных в списке-параметре. В следующем примере на основе списка всех встроенных классов-исключений создается дерево их зависимостей по наследованию:
import inspect, exceptions
def formattree(tree, level=0): """Вывод дерева наследований. tree - дерево, подготовленное с помощью inspect.getclasstree(), которое представлено списком вложенных списков и кортежей. В кортеже entry первый элемент - класс, а второй - кортеж с его базовыми классами. Иначе entry - вложенный список. level - уровень отступов """ for entry in tree: if type(entry) is type(()): c, bases = entry print level * " ", c.__name__, \ "(" + ", ".join([b.__name__ for b in bases]) + ")" elif type(entry) is type([]): formattree(entry, level+1)
v = exceptions.__dict__.values() exc_list = [e for e in v if inspect.isclass(e) and issubclass(e, Exception)]
formattree(inspect.getclasstree(exc_list))
С помощью функции inspect.currentframe() можно получить текущий фрейм исполнения. Атрибуты фрейма исполнения дают информацию о блоке кода, исполняющегося в точке вызова метода. При вызове функции (и в некоторых других ситуациях) на стек кладется соответствующий этому фрейму блок кода. При возврате из функции текущим становится фрейм, хранившийся в стеке. Фрейм содержит контекст выполнения кода: пространства имен и некоторые другие данные. Получить эти данные можно через атрибуты фреймового объекта:
import inspect
def f(): fr = inspect.currentframe() for a in dir(fr): if a[:2] != "__": print a, ":", str(getattr(fr, a))[:70]
f()
В результате получается
f_back : <frame object at 0x812383c> f_builtins : {'help': Type help() for interactive help, or help(object) for help ab f_code : <code object f at 0x401d83a0, file "<stdin>", line 11> f_exc_traceback : None f_exc_type : None f_exc_value : None f_globals : {'f': <function f at 0x401e0454>, '__builtins__': <module '__builtin__ f_lasti : 68 f_lineno : 16 f_locals : {'a': 'f_locals', 'fr': <frame object at 0x813c34c>} f_restricted : 0 f_trace : None
Здесь f_back - предыдущий фрейм исполнения (вызвавший данный фрейм), f_builtins - пространство встроенных имен, как его видно из данного фрейма, f_globals - пространство глобальных имен, f_locals - пространство локальных имен, f_code - кодовый объект (в данном случае - байт-код функции f()), f_lasti - индекс последней выполнявшейся инструкции байт-кода, f_trace - функция трассировки для данного фрейма (или None), f_lineno - текущая строка исходного кода, f_restricted - признак выполнения в ограничительном режиме.
Получить информацию о стеке интерпретатора можно с помощью функции inspect.stack(). Она возвращает список кортежей, в которых есть следующие элементы:
(фрейм-объект, имя_файла, строка_в_файле, имя_функции, список_строк_исходного_кода, номер_строки_в_коде)
Трассировочные объекты также играют важную роль в интроспективных возможностях языка Python: с их помощью можно отследить место возбуждения исключения и обработать его требуемым образом. Для работы с трассировками предусмотрен даже специальный модуль - traceback.
Трассировочный объект представляет содержимое стека исполнения от места возбуждения исключения до места его обработки. В обработчике исключений связанный с исключением трассировочный объект доступен посредством функции sys.exc_info() (это третий элемент возвращаемого данной функцией кортежа).
Трассировочный объект имеет следующие атрибуты:
tb_frame Фрейм исполнения текущего уровня.tb_lineno и tb_lasti Номер строки и инструкции, где было возбуждено исключение.tb_next Следующий уровень стека (другой трассировочный объект).
Одно из наиболее частых применений модуля traceback - "мягкая" обработка исключений с выводом отладочной информации в удобном виде (в лог, на стандартный вывод ошибок и т.п.):
#!/usr/bin/python
def dbg_except(): """Функция для отладки операторов try-except""" import traceback, sys, string print sys.exc_info() print " ".join(traceback.format_exception(*sys.exc_info()))
def bad_func2(): raise StandardError
def bad_func(): bad_func2()
try: bad_func() except: dbg_except()
В результате получается примерно следующее:
(<class exceptions.StandardError at 0x4019729c>, <exceptions.StandardError instance at 0x401df2cc>, <traceback object at 0x401dcb1c>) Traceback (most recent call last): File "pr143.py", line 17, in ? bad_func() File "pr143.py", line 14, in bad_func bad_func2() File "pr143.py", line 11, in bad_func2 raise StandardError StandardError
Функция sys.exc_info() дает кортеж с информацией о возбужденном исключении (класс исключения, объект исключения и трассировочный объект). Элементы этого кортежа передаются как параметры функции traceback.format_exception(), которая и печатает информацию об исключении в уже знакомой форме.Модуль traceback содержит и другие функции (о них можно узнать из документации), которые помогают форматировать те или иные части информации об исключении.
Разумеется, это еще не все возможности модуля inspect и свойств интроспекции в Python, а лишь наиболее интересные функции и атрибуты. Подробнее можно прочитать в документации или даже в исходном коде модулей стандартной библиотеки Python.
Модуль profile
Этот модуль позволяет проанализировать работу функции и выдать статистику использования процессорного времени на выполнение той или иной части алгоритма.
В качестве примера можно рассмотреть профилирование функции для поиска строк из списка, наиболее похожих на данную. Для того чтобы качественно профилировать функцию difflib.get_close_matches(), нужен большой объем данных. В файле russian.txt собрано 160 тысяч слов русского языка. Следующая программа поможет профилировать функцию difflib.get_close_matches():
import difflib, profile
def print_close_matches(word): print "\n".join(difflib.get_close_matches(word + "\n", open("russian.txt")))
profile.run(r'print_close_matches("профайлер")')
При запуске этой программы будет выдано примерно следующее:
провайдер
трайлер
бройлер
899769 function calls (877642 primitive calls) in 23.620 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 23.610 23.610 <string>:1(?) 1 0.000 0.000 23.610 23.610 T.py:6(print_close_matches) 1 0.000 0.000 0.000 0.000 difflib.py:147(__init__) 1 0.000 0.000 0.000 0.000 difflib.py:210(set_seqs) 159443 1.420 0.000 1.420 0.000 difflib.py:222(set_seq1) 2 0.000 0.000 0.000 0.000 difflib.py:248(set_seq2) 2 0.000 0.000 0.000 0.000 difflib.py:293(__chain_b) 324261 2.240 0.000 2.240 0.000 difflib.py:32(_calculate_ratio) 28317 1.590 0.000 1.590 0.000 difflib.py:344(find_longest_match) 6474 0.100 0.000 2.690 0.000 difflib.py:454(get_matching_blocks) 28317/6190 1.000 0.000 2.590 0.000 difflib.py:480(__helper) 6474 0.450 0.000 3.480 0.001 difflib.py:595(ratio) 28686 0.240 0.000 0.240 0.000 difflib.py:617(<lambda>) 158345 8.690 0.000 9.760 0.000 difflib.py:621(quick_ratio) 159442 2.950 0.000 4.020 0.000 difflib.py:650(real_quick_ratio) 1 4.930 4.930 23.610 23.610 difflib.py:662(get_close_matches) 1 0.010 0.010 23.620 23.620 profile:0(print_close_matches("профайлер")) 0 0.000 0.000 profile:0(profiler)
Здесь колонки таблицы показывают следующие значения: ncalls - количество вызовов (функции), tottime - время выполнения кода функции (не включая времени выполнения вызываемых из нее функций), percall - то же время, в пересчете на один вызов, cumtime - суммарное время выполнения функции (и всех вызываемых из нее функций), filename - имя файла, lineno - номер строки в файле, function - имя функции (если эти параметры известны).
Из приведенной статистики следует, что наибольшие усилия по оптимизации кода необходимо приложить в функциях quick_ratio() (на нее потрачено 8,69 секунд), get_close_matches() (4,93 секунд), затем можно заняться real_quick_ratio() (2,95 секунд) и _calculate_ratio() (секунд).
Это лишь самый простой вариант использования профайлера: модуль profile (и связанный с ним pstats) позволяет получать и обрабатывать статистику: их применение описано в документации.
Модуль timeit
Предположим, что проводится оптимизация небольшого участка кода. Необходимо определить, какой из вариантов кода является наиболее быстрым. Это можно сделать с помощью модуля timeit.
В следующей программе используется метод timeit() для измерения времени, необходимого для вычисления небольшого фрагмента кода. Измерения проводятся для трех вариантов кода, делающих одно и то же: конкатенирующих десять тысяч строк в одну строку. В первом случае используется наиболее естественный, "лобовой" прием инкрементной конкатенации, во втором - накопление строк в списке с последующим объединением в одну строку, в третьем применяется списковое включение, а затем объединение элементов списка в одну строку:
from timeit import Timer
t = Timer(""" res = "" for k in range(1000000,1010000): res += str(k) """) print t.timeit(200)
t = Timer(""" res = [] for k in range(1000000,1010000): res.append(str(k)) res = ",".join(res) """) print t.timeit(200)
t = Timer(""" res = ",".join([str(k) for k in range(1000000,1010000)]) """) print t.timeit(200)
Разные версии Python дадут различные результаты прогонов:
# Python 2.3 77.6665899754 10.1372740269 9.07727599144
# Python 2.4 9.26631307602 9.8416929245 7.36629199982
В старых версиях Python рекомендуемым способом конкатенации большого количества строк являлось накопление их в списке с последующим применением функции join() (кстати, инкрементная конкатенация почти в восемь раз медленнее этого приема). Начиная с версии 2.4, инкрементная конкатенация была оптимизирована и теперь имеет даже лучший результат, чем версия со списками (которая вдобавок требует больше памяти). Но чемпионом все-таки является работа со списковым включением, поэтому свертывание циклов в списковое включение позволяет повысить эффективность кода.
Если требуются более точные результаты, рекомендуется использовать метод repeat(n, k) - он позволяет вызывать timeit(k) n раз, возвращая список из n значений. Необходимо отметить, что на результаты может влиять загруженность компьютера, на котором проводятся испытания.
Оптимизация
Основная реализация языка Python пока что не имеет оптимизирующего компилятора, поэтому разговор об оптимизации касается только оптимизации кода самим программистом. В любом языке программирования имеются свои характерные приемы оптимизации кода. Оптимизация (улучшение) кода может происходить в двух (зачастую конкурирующих) направлениях: скорость и занимаемая память. В условиях достатка оперативной памяти приложения обычно оптимизируют по скорости. При оптимизации по времени программы для одноразового вычисления следует иметь в виду, что в общее время решения задачи входит не только выполнение программы, но и время ее написания. Не стоит тратить усилия на оптимизацию программы, если она будет использоваться очень редко.
Следует учитывать, что программа, реализующая некоторый алгоритм, не может быть оптимизирована до бесконечно малого времени вычисления: используемый алгоритм имеет определенную временную сложность и программу, основанную на слишком сложном алгоритме, существенно оптимизировать не удастся. Можно попытаться сменить алгоритм (хотя многие задачи этого сделать не позволяют) или ослабить требования к решениям. Иногда помогает упрощение алгоритма. К сожалению, оптимизация кода, как и программирование - задача неформальная, поэтому умение оптимизировать код приходит с опытом.
Если скорость работы программы при большой длине данных не устраивает, следует поискать более эффективный алгоритм. Если же более эффективный алгоритм практически нецелесообразен, можно попытаться провести оптимизацию кода.
Собственно, в данном примере для модуля timeit уже показан практический способ нахождения оптимального кода. Стоит также отметить, что с помощью профайлера нужно определить места кода, отнимающие наибольшую часть времени. Обычно это действия, выполняемые в самом вложенном цикле. Можно попытаться вынести из цикла все, что можно вычислить в более внешнем цикле или вообще вне цикла.
В языке Python вызов функции является относительно дорогостоящей операцией, поэтому на критичных по скорости участках кода следует избегать вызова большого числа функций.
В некоторых случаях работу программы на Python можно ускорить в несколько раз с помощью специального оптимизатора (он не входит в стандартную поставку Python, но свободно распространяется): psyco. Для ускорения программы достаточно добавить следующие строки в начале главного модуля программы:
import psyco psyco.full()
Правда, некоторые функции не поддаются "компиляции" с помощью psyco. В этих случаях будут выданы предупреждения. Посмотрите документацию по psyco с тем, чтобы узнать ограничения в его использовании и способы их преодоления.
Еще одним вариантом ускорения работы приложения является переписывание критических участков алгоритма на языках более низкого уровня (С/С++) и использование модулей расширения из Python. Однако эта крайняя мера обычно не требуется или модули для задач, требующих большей эффективности, уже написаны. Например, для работы с растровыми изображениями имеется прекрасная библиотека модулей PIL (Python Imaging Library). Численные расчеты можно выполнять с помощью пакета Numeric и т.д.
Отладка
В интерпретаторе языка Python заложены возможности отладки программ, а в стандартной поставке имеется простейший отладчик - pdb. Следующий пример показывает программу, которая подвергается отладке, и типичную сессию отладки:
# File myfun.py def fun(s): lst = [] for i in s: lst.append(ord(i)) return lst
Так может выглядеть типичный процесс отладки:
>>> import pdb, myfun >>> pdb.runcall(myfun.fun, "ABCDE") > /examples/myfun.py(4)fun() -> lst = [] (Pdb) n > /examples/myfun.py(5)fun() -> for i in s: (Pdb) n > /examples/myfun.py(6)fun() -> lst.append(ord(i)) (Pdb) l 1 #!/usr/bin/python 2 # File myfun.py 3 def fun(s): 4 lst = [] 5 for i in s: 6 -> lst.append(ord(i)) 7 return lst [EOF] (Pdb) p lst [] (Pdb) p vars() {'i': 'A', 's': 'ABCDE', 'lst': []} (Pdb) n > /examples/myfun.py(5)fun() -> for i in s: (Pdb) p vars() {'i': 'A', 's': 'ABCDE', 'lst': [65]} (Pdb) n > /examples/myfun.py(6)fun() -> lst.append(ord(i)) (Pdb) n > /examples/myfun.py(5)fun() -> for i in s: (Pdb) p vars() {'i': 'B', 's': 'ABCDE', 'lst': [65, 66]} (Pdb) r - Return - > /examples/myfun.py(7)fun()->[65, 66, 67, 68, 69] -> return lst (Pdb) n [65, 66, 67, 68, 69] >>>
Интерактивный отладчик вызывается функцией pdb.runcall() и на его приглашение (Pdb) следует вводить команды. В данном примере сессии отладки были использованы некоторые из следующих команд: l (печать фрагмент трассируемого кода), n (выполнить все до следующей строки), s (сделать следующий шаг, возможно, углубившись в вызов метода или функции), p (печать значения), r (выполнить все до возврата из текущей функции).
Разумеется, некоторые интерактивные оболочки разработчика для Python предоставляют функции отладчика. Кроме того, отладку достаточно легко организовать, поставив в ключевых местах программы, операторы print для вывода интересующих параметров. Обычно этого достаточно, чтобы локализовать проблему. В CGI-сценариях можно использовать модуль cgitb, о котором говорилось в одной из предыдущих лекций.
Получение байт-кода
После того как получено дерево синтаксического разбора, компилятор должен превратить его в байт-код, подходящий для исполнения интерпретатором. В следующей программе проводятся отдельно синтаксический анализ, компиляция и выполнение (вычисление) кода (и выражения) в языке Python:
import parser
prg = """print 2*2""" ast = parser.suite(prg) code = ast.compile('filename.py') exec code
prg = """2*2""" ast = parser.expr(prg) code = ast.compile('filename1.py') print eval(code)
Функция parser.suite() (или parser.expr()) возвращает AST-объект (дерево синтаксического анализа), которое методом compile() компилируется в Python байт-код и сохраняется в кодовом объекте code. Теперь этот код можно выполнить (или, в случае выражения - вычислить) с помощью оператора exec (или функции eval()).
Здесь необходимо заметить, что недавно в Python появился пакет compiler, который объединяет модули для работы анализа исходного кода на Python и генерации кода. В данной лекции он не рассматривается, но те, кто хочет глубже изучить эти процессы, может обратиться к документации по Python.
Профайлер
Для определения мест в программе, на выполнение которых уходит значительная часть времени, обычно применяется профайлер.
Pychecker
Одним из наиболее интересных инструментов для анализа исходного кода Python программы является Pychecker. Как и lint для языка C, Pychecker позволяет выявлять слабости в исходном коде на языке Python. Можно рассмотреть следующий пример с использованием Pychecker:
import re, string import re a = "a b c"
def test(x, y): from string import split a = "x y z" print split(a) + x
test(['d'], 'e')
Pychecker выдаст следующие предупреждения:
badcode.py:1: Imported module (string) not used badcode.py:2: Imported module (re) not used badcode.py:2: Module (re) re-imported badcode.py:5: Parameter (y) not used badcode.py:6: Using import and from ... import for (string) badcode.py:7: Local variable (a) shadows global defined on line 3 badcode.py:8: Local variable (a) shadows global defined on line 3
В первой строке импортирован модуль, который далее не применяется, то же самое с модулем re. Кроме того, модуль re импортирован повторно. Другие проблемы с кодом: параметр y не использован; модуль string применен как в операторе import, так и во from-import; локальная переменная a затеняет глобальную, которая определена в третьей строке.
Можно переписать этот пример так, чтобы Pychecker выдавал меньше предупреждений:
import string a = "a b c"
def test(x, y): a1 = "x y z" print string.split(a1) + x
test(['d'], 'e')
Теперь имеется лишь одно предупреждение:
goodcode.py:4: Parameter (y) not used
Такое тоже бывает. Программист должен лишь убедиться, что он не сделал ошибки.
Синтаксический анализ
Вторая стадия преобразования исходного текста программы в байт-код интерпретатора состоит в синтаксическом анализе исходного текста. Модуль parser содержит функции suite() и expr() для построения деревьев синтаксического разбора соответственно для кода программ и выражений Python. Модуль symbol содержит номера символов грамматики Python, словарь для получения названия символа из грамматики Python.
Следующая программа анализирует достаточно простой код Python (prg) и порождает дерево синтаксического разбора (AST-объект), который тут же можно превращать в кортеж и красиво выводить функцией pprint.pprint(). Далее определяется функция для превращения номеров символов в их мнемонические обозначения (имена) в грамматике:
import pprint, token, parser, symbol
prg = """print 2*2"""
pprint.pprint(parser.suite(prg).totuple())
def pprint_ast(ast, level=0): if type(ast) == type(()): for a in ast: pprint_ast(a, level+1) elif type(ast) == type(""): print repr(ast) else: print " "*level, try: print symbol.sym_name[ast] except: print "token."+token.tok_name[ast],
print pprint_ast(parser.suite(prg).totuple())
Эта программа выведет следующее (структура дерева отражена отступами):
(257, (264, (265, (266, (269, (1, 'print'), (292, (293, (294, (295, (297, (298, (299, (300, (301, (302, (303, (304, (305, (2, '2')))), (16, '*'), (303, (304, (305, (2, '2')))))))))))))))), (4, ''))), (0, ''))
file_input stmt simple_stmt small_stmt print_stmt token.NAME 'print' test and_test not_test comparison expr xor_expr and_expr shift_expr arith_expr term factor power atom token.NUMBER '2' token.STAR '*' factor power atom token.NUMBER '2' token.NEWLINE '' token.ENDMARKER ''
С помощью возможностей интроспекции удается рассмотреть фазы работы транслятора Python: лексический анализ, синтаксический разбор и генерации кода для интерпретатора, саму работу интерпретатора можно видеть при помощи отладчика.
Вместе с тем, в этой лекции было дано представление об использовании профайлера для исследования того, на что больше всего тратится процессорное время в программе, а также затронуты некоторые аспекты оптимизации Python-программ и варианты оптимизации кода на Python по скорости.
Наконец, интроспекция позволяет исследовать не только строение программы, но и объектов, с которыми работает эта программа. Были рассмотрены возможности Python по получению информации об объектах - этом основном строительном материале, из которого складываются данные любой Python-программы.
